
Добавил в подборку бесплатных сервисов bez-bubna.com еще два скрипта, которыми сам давно пользуюсь.
Анализ логов сервера
На больших проектах настоятельно рекомендуются вести постоянный мониторинг активности поисковых роботов. Владельцам маленьких сайтов тоже не стоит упускать поведение Googlebot и YandexBot из вида. Вдумчивое изучение access.log может дать очень много пищи для размышления.
Особенно актуальна работа с логами на этапе запуска – когда в панелях вебмастеров еще ничего не отобразилось, позиций нет и не может быть, а трафик представлен случайными визитами. В этот момент access.log – единственный надежный источник информации о восприятии сайта поисковыми системами.
Инструмент доступен по адресу: https://bez-bubna.com/free/log.php
Загружаете файл, ждете несколько секунд и получаете следующие отчеты:
- Популярные страницы (с большим числом визитов робота, ссылки с них можно использовать для ускорения индексации других url).
- Страницы с относительно небольшим объемом контента (сюда могут попадать и совершенно нормальные документы, но если роботы ползали по пустым техническим страницам – вы это увидите). Прелесть в том, что эти url не всегда можно спарсить программой для техаудита – ведь в индекс могут попадать и страницы без внутренних ссылок.
- Страницы, отдающие поисковым роботам ошибки сервера (404,403, 500). В ошибках как таковых нет ничего страшного, но нужно убедиться, что ответ сервера во всех случаях именно таков, как вы планировали. Случается, по ошибке администратора сервера блокируются IP поисковых роботов – тогда вы будете видеть нормальный сайт, а вот поисковым ботам придется долбиться в 403. Вариантов возникновения нежелательных ошибок просто тьма, это лишь один пример.
Анализ внутренних ссылок
Внутренняя перелинковка не обладает волшебной силой вытаскивать сайт в топ. Но это не значит, что ей не надо заниматься. У ссылок есть как минимум один доказанный эффект (не считая облегчения индексации) – анкор “подшивается” к тексту страницы, на которую ведет ссылка. Страница-акцептор может искаться по ключу, который соответствует анкору.
Таким образом, можно использовать внутренние ссылки для обогащения документов важной для оптимизатора семантикой. Конечно, проделывать это без системы не очень правильно.
Сервис: https://bez-bubna.com/free/inlinks.php
Мне было лень парсить документы самому и пересчитывать каждый линк. Да и зачем, если любой оптимизатор все равно сперва засунет сайт в Screaming Frog? Оттуда можно взять выгрузку с полной информацией о ссылках и анализировать уже ее.
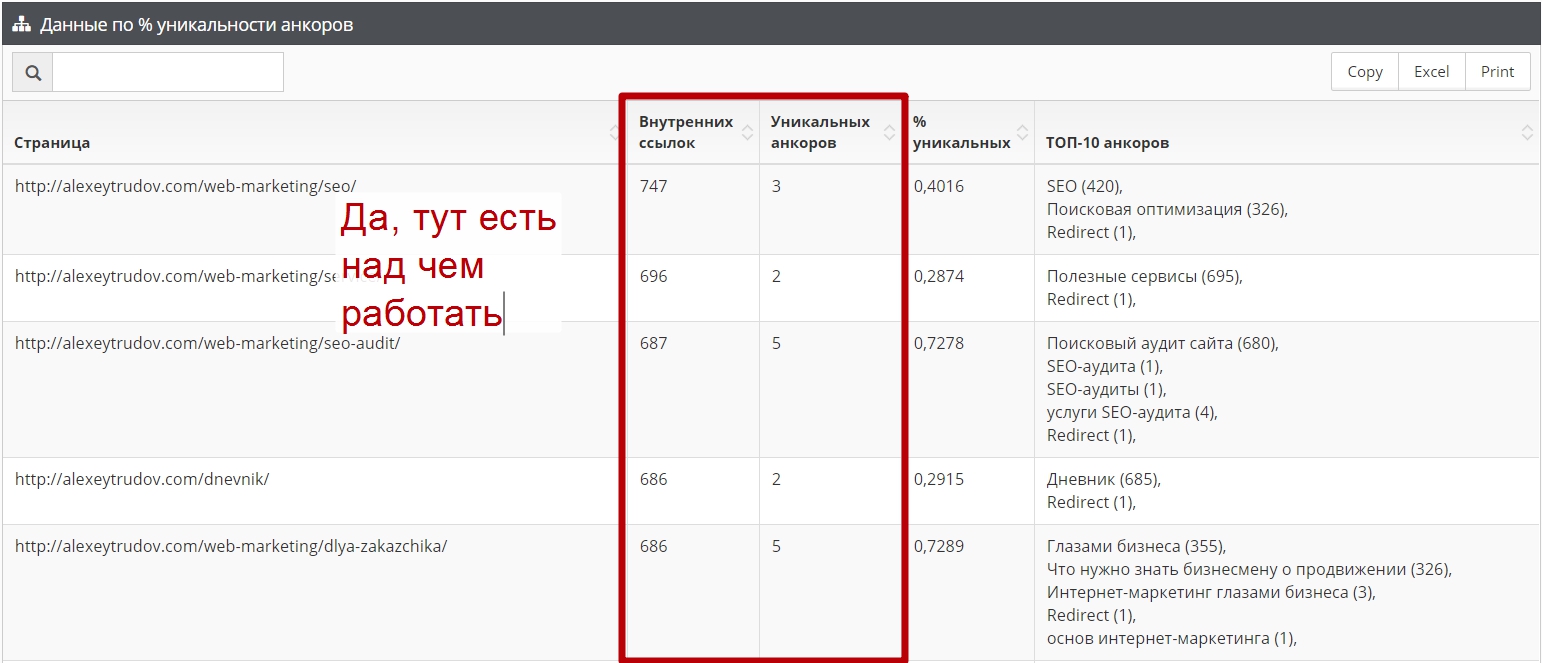
Результат содержит два отчета.
Во-первых, это данные о самых популярных страницах, на которые ведет много ссылок. Потенциально это наиболее сильные страницы, логично будет разметить их по большому количеству ключей. Отчет показывает какие анкоры уже есть и как велико их разнообразие:
Второй отчет помогает найти ссылки с одинаковыми анкорами, но разными целевыми страницами. Такая ситуация может затруднять выбор релевантной страницы.
Оба сервиса бесплатны, но имеют ограничение на размер загружаемого файла (сервера-то не резиновые!) – не более 10 мегабайт. Для небольших проектов этого достаточно.
В дальнейшем выложу аналогичные инструменты с увеличенным лимитом – цена, впрочем, будет вполне символической.
API анализа текста
На прошлой неделе получил сразу несколько вопросов об API для расширенного анализа текста. Удивился такой востребованности и решил не откладывая его реализовать. Документация здесь. API-ключи пока выдаю вручную по запросу. Если у вас биржа контента или потоковое производство статейников – обращайтесь, это должно быть удобнее, чем работа через интерфейс. И как никогда актуально – Баден-Баден продолжает лютовать.



Анализ логов сервера
Интересный инструмент, хотел опробовать, но он постоянно ругается на формат.
common
%h %l %u %t “%r” %>s %O “%{Referer}i” “%{User-Agent}i”
Логи как раз в обычном формате, пробовал в разных кодировках , но все не так.
Пример строки из лога
141.8.132.77 – – [19/Jun/2017:06:28:32 +0300] “GET /wp-content/uploads/2016/02/img.jpg HTTP/1.1” 200 13712 “-” “Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots)”
Пример из сервиса
184.72.146.111 – – [19/Jun/2017:00:10:09 +0300] “GET /seo-zen/ HTTP/1.1” 200 1152 “https://www.google.com/” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.60 Safari/537.17”
Странно, а можно лог куда-нибудь в облако выложить и ссылку мне кинуть? (коммент не буду открывать, никто больше не увидит)
А ещё этот лог можете посмотреть?
Какой? Тот что коментом выше потерял давно)
Радуешь, бро!
😉
Какого максимально размера скушает файл с логами?
10 мегабайт
тоже не пашет
Используйте только файлы в формате common – %h %l %u %t “%r” %>s %O “%{Referer}i” “%{User-Agent}i”. Пример строки в правильном формате: 184.72.146.111 – – [19/Jun/2017:00:10:09 +0300] “GET /seo-zen/ HTTP/1.1” 200 1152 “https://www.google.com/” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.60 Safari/537.17”. Вернуться
Нужен пример файла
Любопытно. Попробовал инструменты. В анализаторе текстов ничего не понял толком 🙂 Чем он качественно отличается от истио-ком?) Ну, кроме добавления биграмм и триграмм. Что они значат так и не понял, хотя и справку почитал. Ну количество сочетаний, окей, это ясно. А как интерпретировать эти значения? Может есть какие-то эталонные? Рассмотри возможность собрать такую статистику и добавить там выделение “плохих” или
“хороших” значений, которые отчетливо отличаются от средних значений в эффективных текстах. Тогда это будет похоже уже на что-то понятное и полезное. Типа вот у вас тут слишком много вхождений этой триграммы, показываешь что зашкаливает. Ну и т.д.
Анализатор логов тоже глянул. Чем ты парсишь их? На PHP?
Почему анализируешь только ботовые запросы? Я думаю ошибочные статусы ответа для любых запросов есть смысл брать, а не только ботовые.
Ну и по размеру – тоже смех на самом деле) 10 мегабайт лог – это около 30к строк. Даже на не сильно посещаемом сайте это лог за пару часов, пришлось резать 🙂 Что ты там наанализируешь с такой истории?) По-хорошему надо брать за месяцок-недельку, ну или хотя бы суточный. По умолчанию логи ротируются раз в сутки.
Считай, при посещении одной страницы не менее пары десятков записей оседает в логах. Даже сотня мегабайт – это не так уж много для access-лога. Ну если только на сервере не отключены запросы для статики (а по-умолчанию это не так обычно).
По поводу “нерезиновости” – можно использовать сжатие gzip на лету. Эти логи очень хорошо и легко жмутся и распаковываются – в 10-15 раз примерно. И хранятся они после ротации имено в gz. Если будет ограничение на 10 мегабайт сжатого лога, это уже более-менее, можно что-то проанализировать… за сутки-половину.
Тем, что заточен на метрики, по которым выявлены значимые различия для текстов под Баден-Баденом и без него.
http://alexeytrudov.com/web-marketing/seo/baden-baden-gde-porogi.html – не видел?
Но я не хочу называть это эталоном и вводить абстрактные “хорошие” и “плохие” цифры, это будет вранье. Все сложнее – включайте голову 🙂 Для продаж конечно волшебная циферка была бы полезнее, но увы.
Ага.
Чтоб не тонуть в инфе. Но вообще да, можно сделать переключатель режимов, чтоб пользователь выбирал как смотреть.
Ну ты даешь! Кто ж тогда платным будет пользоваться, где лимит больше! 😀
Ну и анализ в таком формате, как и писал в посте, нужен в первую очередь молодым, только что открытым к индексу сайтам. Там, где кроме роботов никто не ходит еще.
а, вот оно что. эту статью смотрел несколько дней назад, но в отрыве от сервиса тоже решительно нихрена в ней тогда не понял. Теперь более-менее понятно, спасибо.
А по поводу платности – ну хз. Сомневаюсь, что ты сильно обогатишься на тех, кто чего-то то там анализирует в сайтах-заглушках) Тот, кто может оплатить пользование сервисом на такие сайты просто забивает до поры, не будет он там сидеть ничего анализировать:) Он лучше пойдет сделает ещё 10 таких молодых сайтов. А новичок, который может этим заморочиться вряд ли будет платить. Тут логично бы сделать со сжатием до 10 мегабайт, а платно уже больше и гораздо круче пакетно. Т.е загружает пачку логов за неделю, допустим, и анализирует.
Но в целом мысли годные по поводу анализа ботовых запросов, попробую свои логи поковырять на большем промежутке времени 🙂 Командой строке линукса пофиг на размер файлов 😉
Ну на бесплатных точно не обогащусь 🙂 Курочка по зернышку клюет. В том и прелесть пакета мини-инструментов, что у каждого есть своя небольшая ЦА с конкретными потребностями. По отдельности – прибыль ерундовая, десяток уже нормально.
Мыслей еще много, как-нибудь напишу об этом (или доклад сделаю). Логи – это кладезь информации.
ну то что кладезь оно понятно. Но пока только для технических задач их юзал, про то, что можно что-то по сео извлечь не задумывался.
А так да, причины нагрузки, и всяких школьников-шкодников часто только по ним и можно вычислить на раз. По этой теме можно тоже много писать:) Порой действительно кажется что проще выкатить готовый рабочий анализатор, чем объяснить как этим пользоваться)
Точно
Когда будут доступны платные версии инструментов для больших сайтов?
В течение недели-двух.
Здравствуйте, Алексей! Спасибо за новую программу в арсенале! 🙂
Как Вы полагаете, с чем её стоило бы комбинировать человеку, только начинающему в поисковой оптимизации?
Например, на стадии выведения сайта, внутреннего аудита.
Пожалуйста! 🙂
Конечно, почему нет. Принципы анализа достаточно просты и универсальны.
Алексей, добрый день. Таже ситуация с лог-файлом. Хостинг на Бегете:
Используйте только файлы в формате common – %h %l %u %t “%r” %>s %O “%{Referer}i” “%{User-Agent}i”. Пример строки в правильном формате: 184.72.146.111 – – [19/Jun/2017:00:10:09 +0300] “GET /seo-zen/ HTTP/1.1” 200 1152 “https://www.google.com/” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.60 Safari/537.17”
Ян, у меня тоже бегет)
Насколько я помню, там начало каждой строки ставится хост, на котором зарегистрирован визит. Его нужно удалить из всех строк и тогда должно заработать.
Не совсем понимаю как в начале более 3 тысяч строк удалить название домена
Он же одинаковый?
Открываем в notepad и заменяем “домен ” на пустую строку
А можно попросить ТП настроить логи в другом формате.
Спасибо, заработало, вначале немного подтупил, работая в Notepade++. Не удалялся домен в начале строки. Удалил его и все стало нормально 🙂
Отлично 🙂