
К исследованию о факторах, влияющих на попадание страницы под Баден-Баден поступает много вопросов об одном из них – вариативности.
На самом деле сильное влияние этой метрики не выявлено. Те не менее, различия между “спамными” и “хорошими” с точки зрения Яндекса текстами по нему статистически достоверны. “Плохие” имеют в среднем по больнице меньшее значение показателя. Определенная логика в этом есть.
Как повысить вариативность?
Напомню, что вариативность рассчитывается как “единица минус отношение уникальные леммы/уникальные словоформы”. Показатель я взял из работы Опыт использования машинного обучения при исследовании факторов ранжирования Яндекса.
Очевидно, что вариативность будет высокой, если в тексте:
- сравнительно мало уникальных лемм;
- сравнительно много уникальных словоформ.
По большому счету, нужно ориентироваться на второе условие. Ведь мало уникальных лемм означает информационную бедность контента, постоянные повторы.
Естественные тексты используют слова в разных формах. А вот для SEO-шников “очень-очень старой школы” кажется приемлемым напихать много ключей в прямом вхождении. Если мы вставим 10 раз один и тот же ключ (“пластиковые окна купить”), то получим 3 уникальные леммы и 3 уникальные словоформы. Если же хотя бы в одном случае из 10 напишем “купить пластиковое окно”, то лемм у нас по-прежнему будет 3, а вот словоформ уже 5. Документ станет на шаг ближе к человекообразному.
Пример
Для иллюстрации посмотрим вариативность у образца плохого контента из официального анонса Баден-Бадена:

Да, тут все ох как плохо. Что скажет проверка?
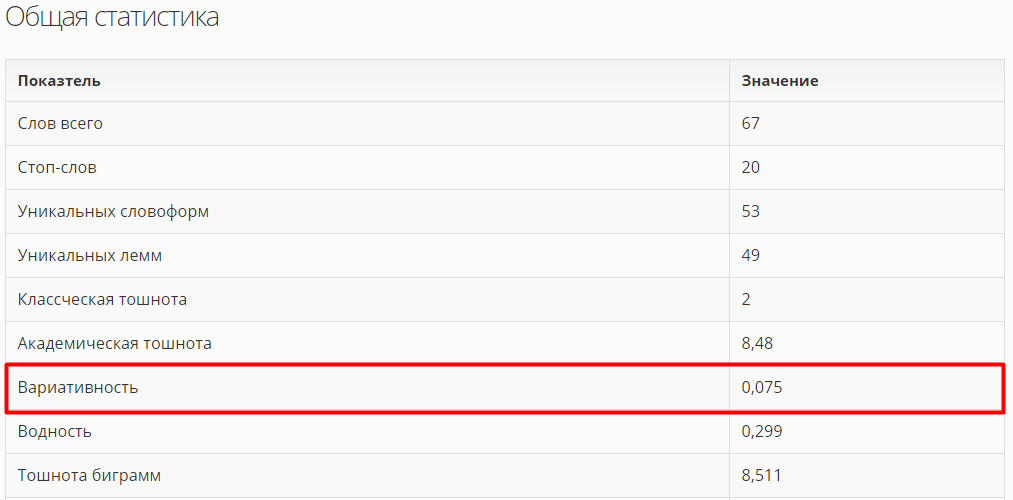
Поменяем теперь буквально 1 словоформу (вместо “SEO-текст” поставим “SEO-текста”). Смотрим вариативность:

Итоги
Можно сильно не беспокоиться о вариативности, если у вас приличный текст. Напоминаю, что все метрики анализа нужны не для того, чтобы втиснуть в их абстрактные границы свои статьи. Они просто помогают быстро выявлять подозрительный контент.
Если же в статью напичкано много ключей в прямом вхождении или ваш копирайтер особо косноязычен, оперирует одними и теми же оборотами – то низкая вариативность об этом просигнализирует.
p.s. Напоминаю, что на этой неделе состоялся мой вебинар по противодействию Баден-Бадену. См. запись и ответы на вопросы.



цикл по всем параметрам? если это так – гуд!
Такой мысли не было, но пару самых интересных метрик наверное стоит рассмотреть.
Где б найти хорошего копирайтера((
То есть достаточно одного прямого вхождения ключа в текст, а дальше разбавляем по-разному?
Не всегда. Скоро на эту тему выйдет мой подробный комментарий в блоге Анны Ященко.
где оцениваете вариативность и иные параметры? откуда скрин?
http://alexeytrudov.com/web-marketing/service/novyie-instrumentyi-dlya-rabotyi-s-kontentom.html
Отписка от поста у тебя на почте не работает
Упс. Спасибо, буду разбираться.
Где какие пороги? Вот у меня вариативность 1 текста – 0,232. А у второго – 0,193. Предполагаю, что тексты нормальные. Но где порог плохого текста?
Какие выводи из этого делать? Хорошие это тексты или плохие?
http://alexeytrudov.com/web-marketing/seo/baden-baden-gde-porogi.html
Добрый день! Все метрики понятны, кроме вариативности. До меня не доходит, чем плох текст, состоящий унилемм, каждая из которых встречается единожды. Получается, что кол-во унилемм и словоформ будет совпадать. А вариативность будет равна 0. Бывает, проверяю в расширенном анализаторе текст, в котором все биграммы и триграммы встречаются по 1 разу, а индекс получается выше нормы. Как так? Или я что-то не понимаю. Хочется разобраться.
Наталия, добрый день!
Конечно же ничем не плох. Но для достаточно объемных текстов такая ситуация вряд ли типична.
Разумеется, тогда на него просто не стоит обращать внимание. Имеет смысл с ним работать только когда и тошнота n-грамм достаточно высока.
Повторюсь в который раз – все пороги условны и могут служить ориентиром только когда больше не на что опираться вообще. Но в любом случае приоритет – это качественный текст и решение принимать автору. А проверяемые параметры способны лишь подсказать, где могут быть проблемы.
Язык, тексты – это сложнейшая вещь, разумеется, ее нельзя запихнуть в несколько простых метрик.
Есть ли какие-то обновленные данные по вариативности и другим показателям для хороших/плохих текстов?
Специально не исследовал. На практике больше опираюсь на выборки текстов по конкретному проекту и/или конкурентам.
Спасибо за ответ! Авторы ругаются на показатель, не могут дотянуть даже до нижней границы (0,23). Проверил свой проект и топового конкурента – среднее значение – 0,19. Может ли вариативность зависеть от тематики?
Конечно может (и должна).