
Вот уже пару месяцев я экспериментирую с word2vec – набором инструментов для анализа текстов от разработчиков Google. Пришла пора не только играться, но и делать с помощью машинного обучения что-то полезное.
Недолго думая, взял и сделал инструмент для подбора тематичных слов к запросам. Вот он (бесплатно, без регистрации): https://bez-bubna.com/free/lsi.php
Зачем нужен еще один сервис подбора синонимов и LSI?
Про использование в SEO связанной с поисковыми запросами лексики (LSI – неправильный, но устоявшийся термин) я уже писал, см. статью LSI в SEO: раскладываем по полочкам. В том числе упомянул немало недостатков и ограничений распространенных подходов к использованию тематикозадающих слов.
Вот еще одна проблема.
На практике сервисы, генерирующие LSI, часто работают с контентом или сниппетами страниц из ТОПа выдачи по запросу. К чем это приводит?
- Выборка для анализа – всего лишь несколько десятков документов. Высок риск собрать только слишком очевидные и потому бесполезные слова.
- Далеко не факт, что изучаемые страницы вообще содержат нужные слова. Факторов ранжирования множество, в ТОПе легко могут держаться сайты с малой текстовой релевантностью (за счет хостовых, ссылочных, поведенческих…).
- Опираясь на тексты конкурентов можно подняться до их уровня, но не сделать лучше.
Я попытался зайти с другой стороны.
Идея сервиса: экспертный контент + word2vec
Использование LSI на основе ТОПа приближает вектор документа с точки зрения Яндекса к документам в ТОП и это не всегда хорошо (см. выше). А что если приближать текст к однозначно хорошим, информативным и ценным материалам?
Где взять такие замечательные материалы? Они существуют, и немало. Надо просто отвлечься от статейников с копирайтингом 1$/тысячезнак и вспомнить, что есть, например, официальные документы с проверенной информацией (законы, инструкции, стандарты лечения). Читайте первоисточники! (с)
Остается собрать серьезную базу таких документов и натравить на нее word2vec, чтобы вычислить связи между разными словами. Благодаря этим связям можно будет по одному слову находить родственные (те, что в заведомо хороших текстах часто ему сопутствовали).
Что получилось?
Получилось не так волшебно, как я хотел. Идея только звучит так просто, на деле работы довольно много. Нужно собрать базу текстов, очистить ее от мусора, перевести в формат, удобный для word2vec, протестировать разные параметры модели…
Я сделал 2 модели по тематикам “медицина” и “юриспруденция”. Для других сфер сервис пока неактуален. Однако то что есть – работает довольно неплохо, можно получать любопытные результаты.
Возьмем простенький пример:
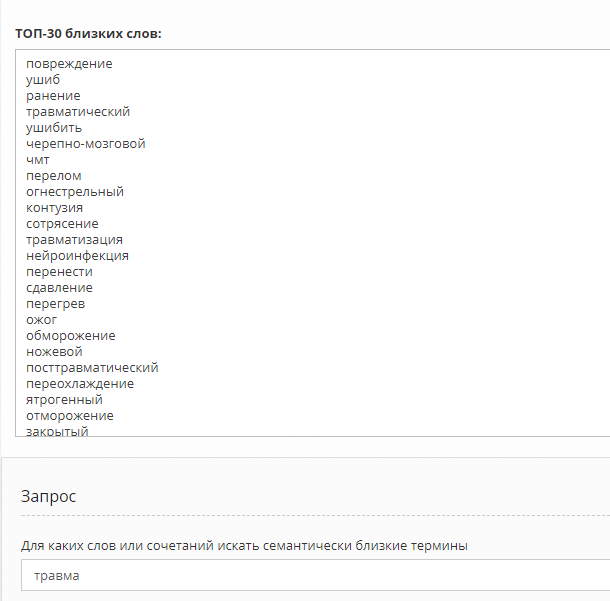
А теперь посложнее:
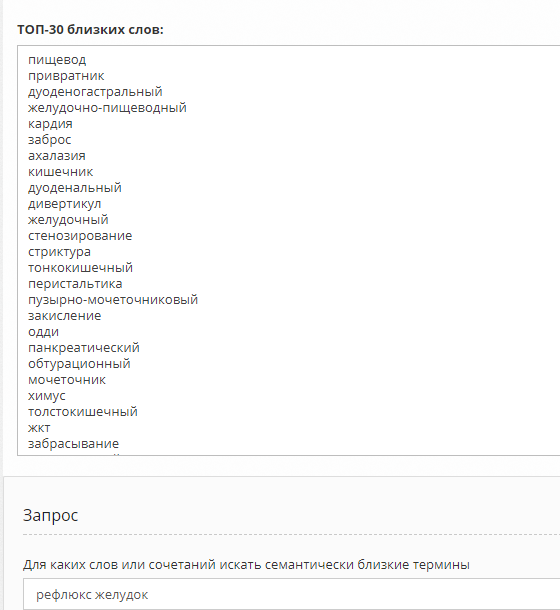
В основном по делу.
Из области права:
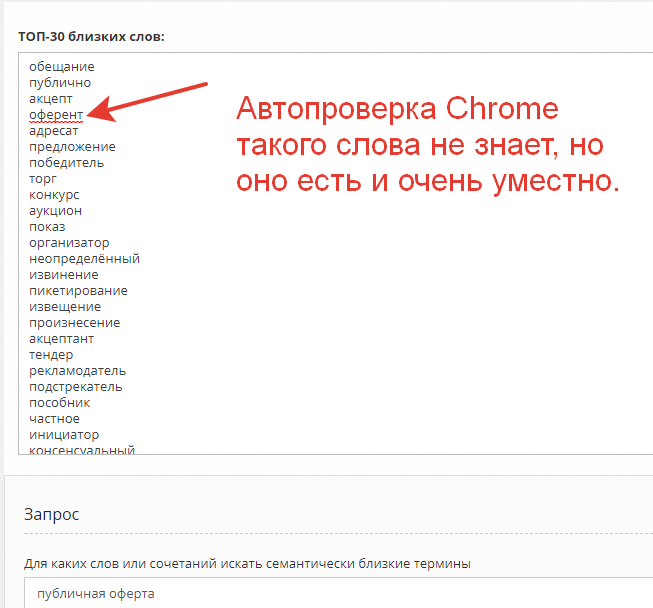
Как это использовать?
Можно и традиционным способом – искать термины каждой отдельной страницы. Но лучше просто познакомить копирайтера с результатами по главным ключевым словам общей темы (рубрика, раздел сайта), чтобы он лучше понимал, о чем здесь вообще речь и глубже разобрался в теме вместо того, чтобы налить воды по привычке. То есть мы получим более качественные и полезные для людей тексты.
(Впрочем, неспециалисту писать информационные статьи в таких серьезных тематиках вообще не стоит, скорее из соображений морали а не SEO. Так что по уму сервис больше для подготовки контента на корпоративные сайты – когда нужно просто грамотно рассказать об услуге, а не описывать “как сделать своими руками”).
Конечно, инструмент сырой. Буду рад замечаниям, примерам некорректной работы и предложениям. Пишите, какие еще тематики хотели бы видеть.



1. Пока что можно юзать не более 10% предложенных вариантов (но это решаемо)
2. Сама идея приближения к экспертным материалам неплохая, но в выдаче ведь не они, а говностатейники по доллару. Возможно сервис в этом плане опережает время.
Спасибо за коммент!
1. Да, это больше для знакомства с тематикой. Ну и надо минусовать слова еще, в примерах очень общие темы. Конечно и обрабатывать результат надо тщательнее, с подключением других источников данных. Думаю об этом.
2. Просто и экспертных и оптимизированных материалов гораздо меньше.
А когда будет 100% волшебство?
когда-нибудь)
Чтобы было ближе к 100%, к этому делу надо добавить немножечко php…
Например?
Спасибо! Очень интересно, все таки тренд!
Под бурж работает? Пошёл тестить.
Нет, все тексты в обучающей выборке были на русском
Спасибо! Хорошая задумка! Протестировала некоторые мед.запросы – результатом довольна.
Отлично!
Есть запросы, где LSI – слова немного галиматья… Особенно при ключевом больше трёх слов.
Да, лучше вводить 2 самых значимых
Алексей, спасибо за интересный сервис, который заставил хорошенько задуматься. Немного предыстории напишу, что бы потом понятнее сформулировать вопрос:
1. Работаю в основном под Украину. Тематики в основном коммерческие: бытовая техника, светильники и т.д.
2. В своем арсенале для сбора тематикозадающих фраз использую:
а). https://arsenkin.ru/tools/sp/
б). руками и глазами собираю подсветки
Словом все делаю “как книжка пишет”.
В принципе, думаю, что данного арсенала на данном этапе мне достаточно. Возможно ошибаюсь. но что поделать, как умею:)
К вам такие вопросы:
1. Есть ли в вашем сервисе привязка по регионам или он просто собирает более качественные документы по разным странам в рамках одного языка (т.е. документы на русском но в разных странах, например СНГ). Т.е., как мне знать, что для Украины данные из этого сервиса могут подойти. Или для любого из регионов России, которые не Москва или СПБ?
2. Подойдет ли вообще сервис для коммерческих тематик?
3. Рекомендуете ли вы применять полученные слова в тексте (добавлять конкретно в ТЗ) или просто стоит дать их копирайтеру на заметку. А он уже пускай тогда вникает в тему и с точки зрения “эксперта” пишет просто мега-полезный текст?
Какие тематики интересны:
1. Спорт.
2. Технологии.
3. Коммерция: недвижимость, товары для дома и отдыха, автомобили и техника, компьютеры.
1. Без привязки.
2. Отчасти. Для описания услуг текстовая релевантность весьма важна.
3. Просто на заметку. Не факт что результаты обязательно правильные, не стоит полагаться на любой сервис слишком сильно.
Тематики взял на заметку, спасибо.
Было бы интереснее на любую тематику. А так, пока бесполезная вещь..
Были бы интересны тематики бизнес, строительство.
Интересно, что выдало бы по запросам типа “как открыть магазин/кафе …” и т.д.
Кулинария была бы интересна и народная медицина. Очень многим бы понадобился такой сервис
Может стоит скормить этому нейро-инструменту тексты из Википедии по теме?
Да, это один из вариантов. Может получиться неплохое качество.
А как вы парсите текст из документов? Может решение этого вопроса ускорило бы процесс.
Парсинг не проблема, проблема найти хорошие источники.
А, например, какой объем текста был “заряжен” под тематику Медицина?
Что-то около 400-500 мегабайт.
Интересна тематика грузоперевозок и переездов.
Алексей, а по этой теме есть какие-то мысли: https://searchengines.guru/showthread.php?t=972525 ?
Неделю назад смотрел – тогда ничего принципиально не поменялось с момента доклада на SEMPRO: http://alexeytrudov.com/web-marketing/seo/trafik-iz-google-c-minimalnyimi-zatratami-sempro-2017.html
По последним нескольким дням еще толком не отслеживал ситуацию.
У меня сайт присел прилично в первый ап “Фреда”, во второй заход “Фреда” просто провалился ниже плинтуса ((( Многие другие сайты, живут нормально.
Почитал по ссылке, но там презентация попала в список “Запрещенных сайтов”.
Можно как-то увидеть ваши материалы по Фреду? Очень любопытно!
Это была последняя капля 🙂
http://alexeytrudov.com/prezentatsii/
Бухгалтерия интересна
Алексей, есть ли изменения по улучшению сервиса с момента его запуска? На сколько полученные данные актуальны для проверяемых фраз и на сколько картина дополняет основные известные слова, лежащие на поверхности?
Пока нет изменений, понемногу делаю вторую версию, но скорее из интереса а не как рабочий проект.
Не изучал этот вопрос детально. Буду рад если проведете такое сравнение на показательной выборке.
Алексей, а Вы не пробовали строить и сравнивать вектора не только для слов, но, и для текстов?
Думаю именно таким образом ПС могут сравнивать тексты на уникальность (информационную, а другая им наверное не сильно и интересна)… А как им еще сравнивать миллиарды текстов (не каждый с каждым же).
А то вот копирайтеры-рерайтеры пишут-пишут нам тексты… А они все не попадают и не попадают в ТОПы… Может потому что это “псевдоуникальные” тексты?
Чуть-чуть игрался с doc2vec тоже но до минимального практического применения пока не дошел. Идея вообще перспективная, конечно.