
В последние несколько месяцев неспешно изучаю машинное обучение. Неспешно – потому что и без него неплохо справлялся с текущими задачами. Также хотелось сначала получить теоретическую подготовку. Использовать machine learning на практике можно и без математических знаний – но приятно разбираться в том, что ты делаешь, а не просто скармливать данные готовым решениям, которые делают 99% работы.
Сегодня наконец дошли руки повозиться с одним из таких решений – знаменитой библиотекой Word2vec, которая была создана работниками Google. Подробное и точное описание каждый может загуглить самостоятельно. Я скажу только, что инструмент позволяет свести воедино информацию о том, какие слова встречаются в похожих контекстах, а значит – связаны друг с другом по смыслу. Все это переводится на язык математики – в векторное пространство, с которым удобно работать.
Для примера я спарсил чуть больше тысячи статей о SEO и загрузил получившийся файлик на 15 мегабайт в python-оболочку к оригинальному Word2vec. Обучающая выборка, конечно, слишком мала для настоящего текстового анализа. Но поиграться и пощупать возможности годится.
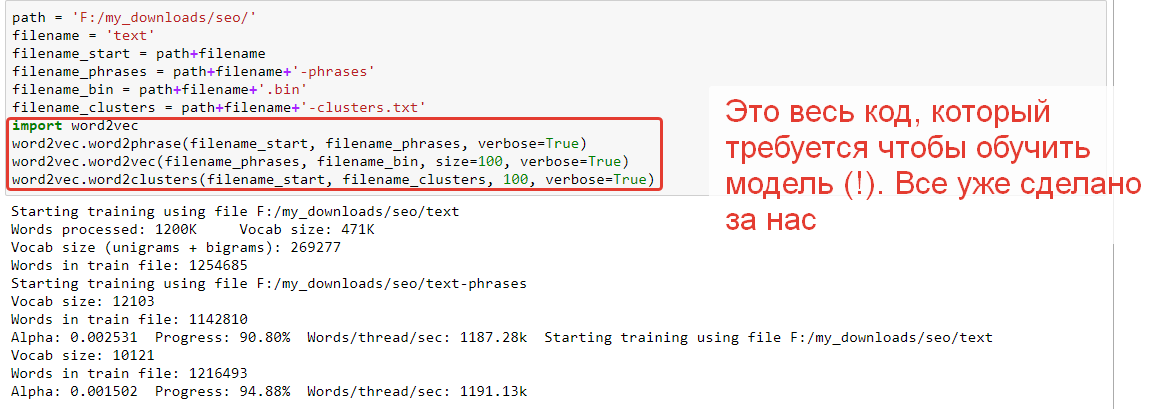
Зададим простую задачку – найдем слова, похожие на “seo”:

Чуть-чуть допилим код вывода:

Кое-что правильно, но не все. Явно закрались статьи немного не по теме и сбили модель в “репост бесплатно”.
Узнаем слова, похоже на “google”:
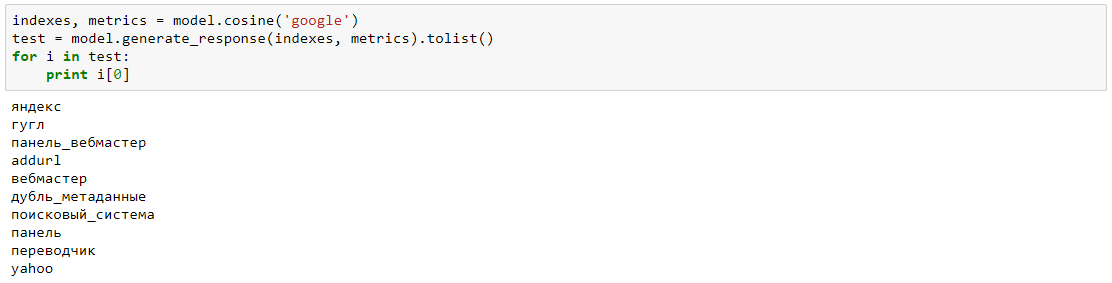
Весьма близко. Я даже не ожидал, что можно это вытащить всего из тысячи статей.
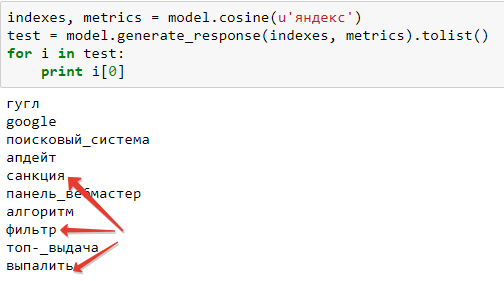
Для Яндекса результат несколько более эмоциональный:
Задачка чуть посложнее – с использованием нескольких слов. Поищем термины, близкие к “заголовок title”, кроме тех, что связаны с title у картинки:
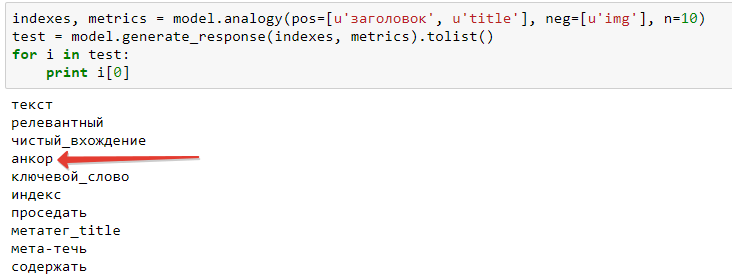
Модель напоминает, что title бывает еще и у ссылок. Заминусуем слово “линк”: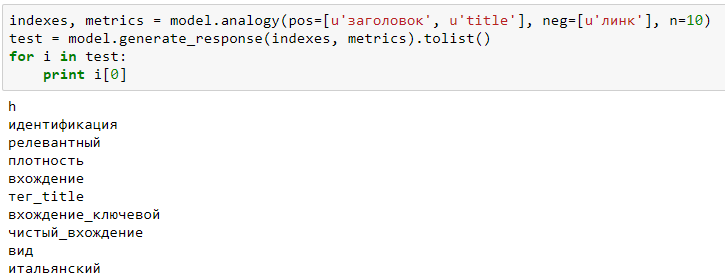
Набор поменялся и стал более похож на дело (только “итальянский” в конце смущает, но у него, на десятом месте, минимальное сходство).
Итог: даже обученный на малом объеме тематичного текста, Word2vec способен уловить множество связей между словами.
Файлик с кодом в html-формате: http://alexeytrudov.com/word2vec_seo.html
Как это можно использовать на практике?
Первое что приходит в голову – искать тематичные слова – то, что принято называть LSI. Более того, в одном из докладов сотрудники Яндекса сами упомянули Word2vec как один из источников расширений запросов, которые должны быть на “хорошей” странице.
Другие варианты:
- Кластеризация поисковых запросов.
- Кластеризация заголовков страниц на сайте для улучшения перелинковки и тегирования. (Улучшение – за счет того, что поиск похожих материалов идет не только по вхождению конкретного ключа, но и близких к нему по смыслу).
- Генерация текстов, которые обладают не только технической уникальностью, но и несут некий уникальный смысл.
- Наоборот, определение текстов, наполненных “водой” (самый простой подход – анализ близости заголовка и текста, а вообще метрик качества можно найти много).
- Классификация запросов/документов/сайтов по тематикам.
Что там с машинным обучением вообще? Очередная смерть SEO?
Не раз и не два видел высокомерные комментарии – дескать, у поисковиков сейчас там все на машинном обучении, куда там бедным SEO-шникам за ними угнаться! Пора проситься на завод дворниками! Что интересно – чем дальше человек от математики и программирования, тем более категоричные заявления он делает. Самые вдохновенные статьи про нейросети написаны гуманитариями. А те же доклады от разработчиков Яндекса битком набиты нерешенными проблемами и новыми вызовами.
Отвечу по пунктам, чтобы было куда сослаться в случае чего:
- Машинное обучение используется в поисковых системах уже очень давно. Откройте “Введение в информационный поиск” (2008 год!) и убедитесь. А ведь это учебник, он излагает уже устоявшиеся факты.
- Новые алгоритмы не так уж сильно улучшают качество поиска – потому что и без них уже реализована бездна “наворотов”. Для Палеха, например, приводилась цифра прироста pFound всего 1,6% (в масштабах миллионов запросов действительно много, но можно ли сказать, что это кардинальное изменение рынка?).
- Даже обученная должным образом модель на основе суперсовременных алгоритмов ошибается. Тем более в такой сложной области как веб-поиск, работе с постоянно меняющимся Интернетом. Кстати, противодействие ушлым SEO-шникам – тоже непростая вещь. Иначе зачем вводить репрессии вроде Минусинска или Баден-Бадена? Отсекали б накрутку на автомате и все. Поэтому идеального поиска нет и в ближайшее время не предвидится. Всегда остаются возможности для воздействия. И просто необходимость в “белой” оптимизации – чтобы робот корректно воспринимал сайт.
Наконец. Мощь машинного обучения доступна не только поисковым системам для гнобления сеошников. Используя готовые инструменты, в том числе выложенные самими поисковиками в свободный доступ, можно существенно расширить собственный арсенал для исследований и практической работы. Да, собрать столько же данных, сколько есть у Яндекса, непросто. Ну и что? У поисковиков задачи тоже масштабнее, чем у нас.



>Генерация текстов, которые обладают не только технической уникальностью, но и несут некий уникальный смысл.
вот про это можно поподробнее? каким образом?
ну нашли мы несколько “тематических” слов.. и что?
На моих текстах модель слабо обучена, поэтому не показал. Там можно строить довольно сложные аналогии, узнавать по сути новые сущности. Например, задаем запрос “что относится к Германии так же как Париж к Франции” и получаем Берлин. То есть по сути сгенерировали факт из реального мира. Это и есть смысловая уникальность. Конечно, только Word2vec тут недостаточно, надо туда что-то подавать на вход и связывать результаты. Но это важное звено.
Я даже 30% того что написано понял)))
Возможно стоит посмотреть и на яндексовский catboost, они его недавно анонсировали
https://tech.yandex.ru/catboost/
Да, тоже изучаю, есть некоторые идеи по использованию.
В случае с яндексовским катбустом смущает, что это методы обучения с учителем,нужны обучающие наборы. Т.е. получается какой-то субъективизм-все зависит от того кто и как составит эти наборы.
Конечно, можно предположить что яндекс типа уже научен, и его результаты рассматривать как обучающий набор и тогда, в теории, обучив модель по топ-20 яндекса можно научиться предполагать насколько текст близок к “хорошему” в понимании яндекса по тем или иным ключевикам.
Так в лоб вряд ли получится. На попадание в ТОП влияет слишком много факторов – не только текстовых.
Алексей, добрый день.
В последнем письме (от 9 числа) промокод указан к использованию до 3 августа. Вы ошибочно скопировали промокод с прошлого письма или просто дату не изменили? Просто я ввожу код, а он не срабатывает.
Елена, да, ошибочно скопировал, промокод кончился.
Спасибо за замечание, давайте начислю вам персональный бонус за помощь. На e-mail комментария или другой?
Алексей, спасибо, буду рада. Почта как в комментарии.
Отлично, добавил 500 лимитов.
Спасибо!
Интересно. Я как-то спрашивал у народа за такую задачку – http://mfc.guru/threads/generacija-title-stati-na-osnove-kontenta.488/
Никто ничего лучше дёрганья первой фразы текста так ничего и не предложил, не придумал. Интересно, что думаешь ты по этому поводу.
Похоже что эта либа может помочь в решении такой задачи, правильно я понимаю?
Да, может помочь написать более “человечный” тайтл. Или нагенерить с ее помощью разных вариантов и тестировать.
По теме – я бы попробовал второй вариант. Выделил бы частотные n-граммы и посмотрел тайтлы по ним в выдаче. Например, можно взять 3 самые частые триграммы/биграммы, брать тайтл страницы, которая показывается по ним всем и чуть-чуть модифицировать тем же w2v.
В конце – отличный ответ всем паникёрам, все по полочкам, спасибо, Алексей
Дмитрий, рад, что понравилось!
Алексей, С момента “Зададим простую задачку – найдем слова, похожие на “seo”:” какой части программы вы задаете эту задачу? Откуда берутся данные для решения этой задачки – полагаю должен быть путь к файлу?
Александр, да, сначала нужно загрузить модель (метод load).
Посмотрите полный код, скриншоты которого я даю в статье, все будет понятно: https://alexeytrudov.com/word2vec_seo.html