
Попарное сравнение – одна из методик определения текстовых фильтров в Яндексе. Очень широко применяется оптимизаторами, лежит в основе ряда SEO-сервисов (инструменты Арсёнкина, Кулакова и Пиксель.Тулс).
Суть метода, кратко
- Проверяется позиция сайта по запросу.
- Затем в Яндекс отправляется тот же запрос, для которого с помощью операторов область поиска сужена на два сайта – “пациента” и конкурента, который в обычной выдаче находится выше. То есть запрос типа “ключевое слово (site:patsient.ru | site:konkurent.ru)”.
- Если в расширенном поиске наш сайт выше конкурента – значит, на него наложен фильтр.
- Смена релевантного url – дополнительный негативный признак.
Есть много вариаций подхода (например, сравнение за раз нескольких сайтов, сравнение не с одним конкурентом, а с десятком, последовательное сравнение со всем ТОП-100).
Любопытно, что никаких экспериментальных обоснований для методики в публичном доступе найти не удалось. Нет и внятного теоретического обоснования. Лишь ничем не подкрепленное утверждение, что при использовании операторов расширенного поиска снимаются текстовые санкции.
Кстати: оператор “()” в Яндексе вроде бы должен быть отменен. Но именно для запросов с оператором site: работает корректно – по крайней мере в выдаче действительно остаются только страницы с указанных доменов.
Я решил исправить положение и сделал несколько простых наблюдений.
Наблюдение 1: релевантная страница в основном поиске и полученная с помощью “site:” часто отличаются
Для начала я попробовал изучить один из элементов метода – выдачу, которая получается при использовании оператора site:. У меня нашлось несколько очень любопытных объектов для изучения. Это сайты, которые я создал, готовя доклад на BDD об учете возраста документа. Там используется генерированный по особой методике контент. На сайтах есть страницы-близнецы, заточенные под одни и те же запросы и обладающие очень близкой текстовой релевантностью.
Схема генерации страниц (слайд из доклада):
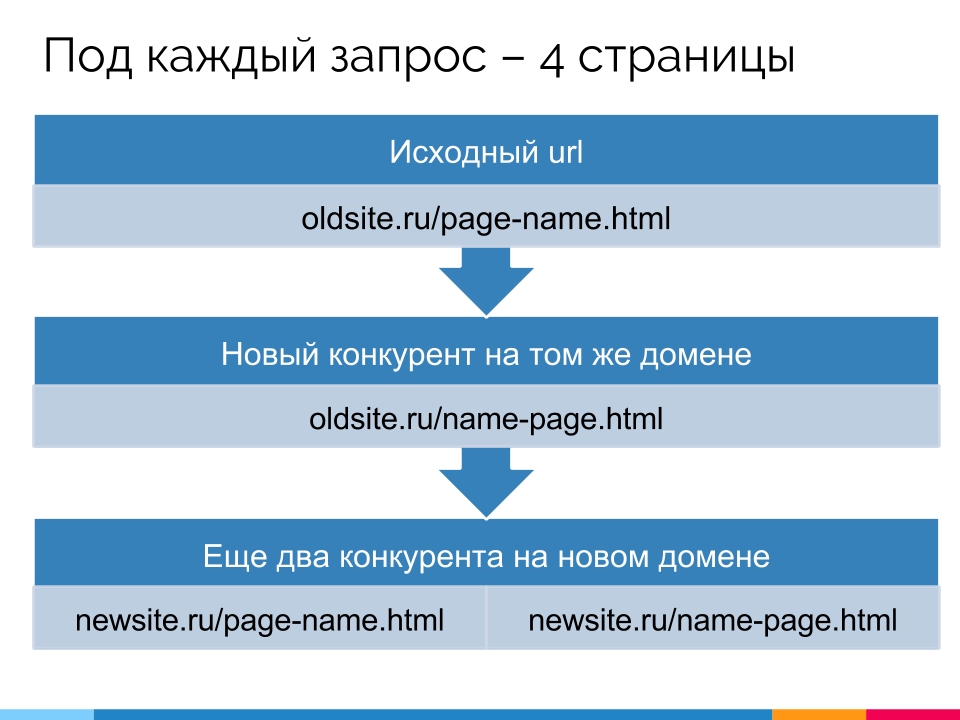
Анализ site: для старых доменов
В эксперименте использовано 522 запроса (по 6 на пару страниц-близнецов) для 3 сайтов. Сначала проверялись позиции в Яндексе по запросу без оператора, затем добавлялся site:domen.ru.
Для 28 запросов релевантная страница в нормальном поиске и в поиске с оператором оказалась различной.
При этом:
- в 26 случаях в нормальном поиске показывалась молодая страница, а в расширенном – старая.
- в 2 случаях одна старая страница сменилась другой старой.
Напомню, разница в возрасте между “близнецами” – более трех лет.
Напрашивается идея, что возраст имеет большее значение для поиска с оператором, чем для нормального (альтернативная гипотеза – в расширенном поиске не свирепствует многорукий Бандит). Выборка недостаточно велика, чтобы делать обоснованные выводы, поэтому пока просто запомним сам факт.
Анализ site: для молодых доменов
Здесь картина гораздо интереснее.
Несовпадение релевантного url в обычном и расширенном поиске проявилось на 301 запросе из 522. То есть в 58% случаев (!). На самом деле различия могут быть еще больше – для нескольких десятков запросов страницы с домена не были найдены в ТОП-100 и не рассматривались.
Еще более интересный момент: очень часто релевантная при поиске с оператором определялась неверно.
Запросы использовались достаточно длинные – из 5 и 6 слов. Поисковые фразы генерировались по такой схеме: “слово1 слово2 {уникальное слово} слово4 слово5”. Было 6 групп запросов, внутри каждой из них ключи отличались только одним термином.
Каждому запросу соответствовало как минимум одно точное вхождение на двух страницах-близнецах. Более того, на других страницах сайта уникальное слово не использовалось.
Так вот, при запросе с оператором очень часто уникальное слово игнорировалось. По ряду запросов весь ТОП-5 был забит страницами, которые вообще его не содержали. А документы с вхождением в title и h1 оставались где-то на 7-10 позиции.
Количественную оценку я делать поленился. Просто проверил вручную 30 разных запросов, чтобы убедиться, что наблюдаемое явление – не случайный баг. Действительно, при поиске с оператором на длинных запросах в ТОП-1 постоянно показываются не адекватные интенту страницы. Зато в нормальном поиске Яндекс справлялся отлично.
Промежуточный вывод: при использовании “site:” применяется иной алгоритм ранжирования
Все изложенное выше наводит на мысль, что при ранжировании внутри домена используется другой алгоритм, сильно отличающийся от основного. Как минимум иначе рассчитывается текстовая релевантность.
Показательно, что свистопляска с релевантными наблюдается именно на новых сайтах, где все документы имеют одинаковый возраст. В таких условиях ранжировать приходится чисто по текстовым характеристикам, что и вскрывает несовершенство применяемого в расширенном поиске алгоритма.
Наблюдение 2: при попарном сравнении проблемы с выбором релевантной сохраняются
Теперь я тестировал те же запросы, но уже применяя попарное сравнение для старого и нового доменов. Как несложно предположить, тотально доминировали старые сайты и страницы. Url со старого домена занимали по 10-15 мест в выдаче. Причем url с нового домена с самой высокой позицией по-прежнему очень часто оказывался не релевантным запросу (и совпадал с тем, что обнаружен при помощи одиночного site:).
Можно было предполагать, что в случае поиска по нескольким сайтам подключается более продвинутый основной алгоритм. Однако эта гипотеза не подтвердилась. Все указывает на то, что в случае попарного сравнения действуют те же закономерности, что и при поиске с одиночным “site:”.
Наблюдение 3: при попарном сравнении могут расти позиции незафильтрованного сайта
Все, кто использовал методику для анализа спамных текстов наверняка видели, как сайт улучшает свои позиции в поиске с операторами. Однако чтобы признать методику полностью валидной этого недостаточно. Нужно, чтобы росли только такие сайты. Нельзя строить достоверные выводы исключительно на позитивных примерах. Тем, кто не согласен с этим абзацем, предлагаю для начала загуглить “положительная предвзятость”. А мы идем дальше.
Посмотрим, как себя ведут априори не-переоптимизированные страницы.
Возьмем страницу справки “Чем отличается качественный сайт от некачественного с точки зрения Яндекса?”: https://yandex.ru/support/webmaster/yandex-indexing/webmaster-advice.xml. Весьма маловероятно, что на нее наложены санкции, не так ли?
Я разбил текст на 125 цитат из 4-8 слов. Сначала спарсил выдачу по ним без операторов. Затем добавил к запросу попарное сравнение yandex.ru с сайтом, который имел в обычной выдаче максимальную позицию. Повторял по 3 раза в сутки в течение 5 дней.
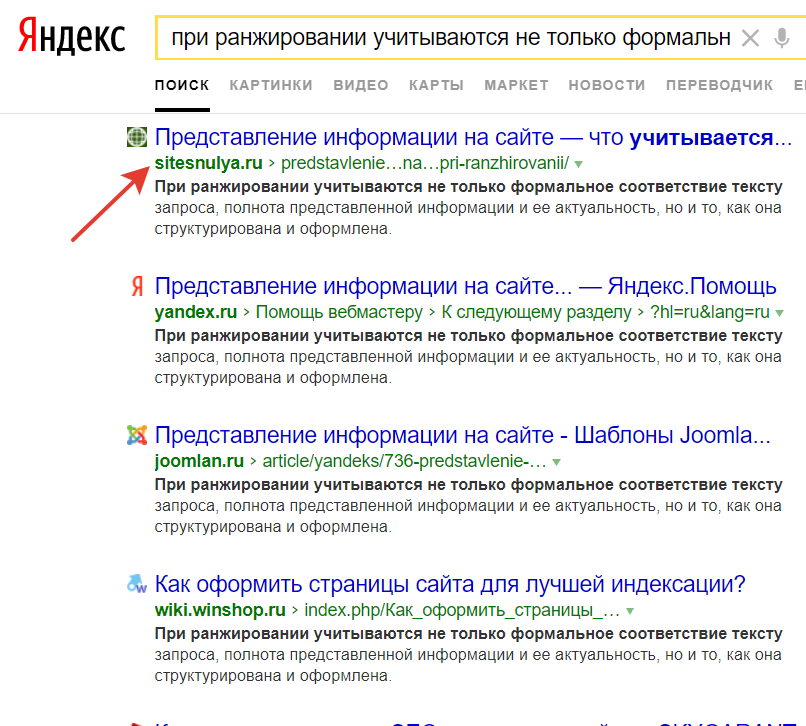
В каждой из проб оказывалось 10-13 запросов, по которым в основной выдаче страница Яндекса не была ТОП-1, а вот в попарном сравнении оказывалась в ТОП.
Например (обычный запрос):
С операторами:
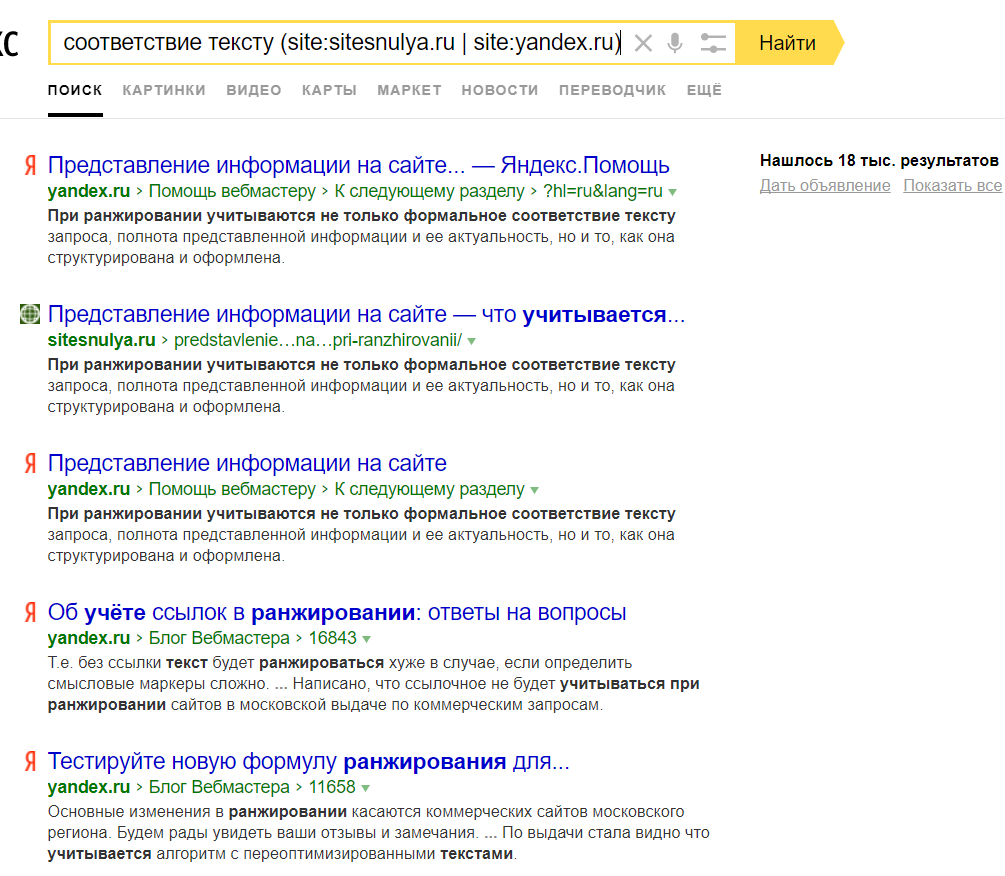
Состав подобных запросов время от времени менялся (Бандит?). Однако как минимум 5 запросов демонстрируют описанное выше поведение стабильно.
Обратите внимание: наблюдения сделаны для первой попавшейся, выбранной наугад страницы.
Выводы
- Поиск с использованием site: качественно отличается от обычного. Вероятно, в этом случае действительно не учитываются пост-фильтры, но наверняка есть и масса других различий.
- Смена релевантной страницы при попарном сравнении не является свидетельством проблем.
- Полагаться на поиск с site: как методику определения релевантной запросу страницы неправильно (а зачастую даже вредно!).
Все это, однако, не значит, что попарное сравнение нужно исключить из арсенала. Очевидно, что если сайт на позиции 80 в последовательно побеждает всех своих конкурентов, это серьезный сигнал, что с посадочной страницей что-то не так. Просто потому что такие существенные различия не слишком часто встречаются. (Другой вопрос, что еще более серьезные сигналы можно получить из Метрики или системы мониторинга позиций).
А вот применять методику “в лоб”, чтобы нивелировать влияние Бандита, делать вывод именно о текстовых санкциях или автоматизированно очищать выборку в масштабных исследованиях – очень, очень спорный подход.
Планирую продолжить исследования по вопросу. Сегодня я только слегка попробовал его на зуб – все наблюдения достаточно просты и сделаны на небольших выборках. Думаю, самое интересное впереди.



http://joxi.ru/12M5eoYI4Qj6E2 а более целевой аудитории рекламодатель не подобрал? по его мнению у сеошников запоры что ли часто случаются?
Ахаха)
RTB такой RTB.
я сначала не понял, подумал что это прямой рекламодатель) потом обновил, увидел что ртб
На сеошников труднее всего таргет. Могут искать что угодно вообще
МЕРСИ!)))
Попробуйте провести аналитику на запросах в формате “ключевое слово (url:patsient.ru* | url:konkurent.ru*)”
Тоже пока еще работает, и выдача от site отличается, иногда сильно..
Спасибо за идею! Взял на заметку.
Алексей, спасибо за информацию основанную на доводах, а не на домыслах! Продолжайте в том же духе! 🙂
Пожалуйста и благодарю за приятный комментарий.
Дилетантские вопросики
1. А оно (такая возня) того стоит? Может быть, лучше сайт содержать в приличном виде (как требуют люди и поисковики)? 🙂
2. “Если в расширенном поиске наш сайт выше конкурента — значит, на него наложен фильтр. ” – вопрос на кого наложен: на сайт или на конкурента? 😉
1. Лучше 🙂
2. На изучаемый сайт. Гипотеза в основе метода – что в расширенном поиске фильтры снимаются. Логично, что со снятым фильтром сайт занимает более высокую позицию.
Допустим, фильтр диагностирован методами описанными выше. Также есть другие веские причины что есть фильтр. Как выходить из него? (Переписать текст, я так понимаю, с учетом “естественности”, уменьшения спама), И самое главное – примерный срок выхода из-под этого фильтра? Новый текст к примеру проиндексирован, но заметных улучшений нет, Из топ-30 зашел в топ-20, прошло 5 дней с моиента отправки в переобход в ЯВМ urla с новым текстом.
Собственно, вся статья о том, что результат по этой методике – совсем не веские причины полагать,что это есть фильтр.
И еще меньше уверенности в том, что это именно текстовый фильтр.
Нужно изучать страницу и конкурентов, прежде чем делать какие-то выводы. Универсальной методики нет. Со сроками та же история.
Сильнейший материал! Спасибо!
И как теперь искать релевантную страницу на сайте по версии Яндекса?)
Спасибо за оценку 🙂
Просто берем не ТОП-1 при поиске с site:, а первый результат в реальной выдаче (даже если до него приходится основательно листать из-за низкой позиции).
Результаты проверки этих сервисов (арсенкин и coolakov) очень коррелируют с анализом текстов без бубна. Большую выборку не делал но на глаз имеем: 10 сайтов (интернет магазин и карточки товара, появившиеся одновременно и относительно недавно весной-летом этого года). Сайты имеют схожий возраст и уровень ТИЦ, а так же ссылочный профиль. Конечно это не близнецы братья, но что имеем. Прогоняя сервисом на переоптимизацию по запросам , которые сгруппированы на одну страницу (купить ххх, заказать ххх, ххх, продажа ххх, цена ххх) имеем интересную разбивку. 30% сайтов сидящих глубоко за 20-30 позиции по 75% запросов имеют по этим запросам показатель наличия фильтра. Вторая группа фильтра не имеет, но позиции болтаются 10-20. И третья группа в ТОПе почти по всем запросам. Так вот все эти 3 группы имеют разную закономерную схожую водность страниц. Первая группа имеет водность около 0.25-0.29 и соответственно на них и сервисы показывают фильтры за переоптимизацию. Вторая группа имеет водность 0.20-0.25 и соответственно фильтров нет, но и позиции никакие. А вот третья группа имеет водность 0.15-0.20 и находится в ТОП. При этом текст в третьей группе читать почти нельзя. Хоть и воды в них нет, но смысл понять невозможно. Почти набор бредогенератора, но уникальный и сухой. ПФ скорее должен был отдать свой вес второй группе, судя по качеству сайтов, картинок, описаний. Но в ТОПе именно сайты с уникально минимальной водностью. И еще наблюдение. Сами seo тексты из ТОПа имеют водность не уникально низкую. (0.23-026), но вот именно на сайте низкая водность достигается за счет меню, и прочих элементов самого сайта. Так что вот такие наблюдения. Было бы интересно проверить сервисы по переоптимизации на большой выборке, но я думаю есть прямая зависимость данных, показываемых сервисами, позициями, водностью текстов и санкциями поисковиков
Роман, интересные наблюдения и мысли, спасибо!
Алексей, спасибо за исследование. Уже несколько лет назад стал замечать, что самая релевантная страница в общей выдаче и по site: отличается. Задавал вопрос в поддержку Яндекса. Тогда это посчитали за ошибку. Хотя может быть в то время и начали разделять формулы ранжирования. 🙂
Сергей, рад, что пригодилось!
Все может быть. С другой стороны, судя по докладам яндексоидов, уже довольно давно используются метафакторы (см. тут), рассчитываемые с учетом выборки, которая получена на ранних стадиях ранжирования. В случае с одним сайтом эта выборка явно будет смещенной. Впрочем, несколько лет для поиска – это много. В общем, дело ясное что дело темное)
Здравствуйте. Работает ли данная конструкция, при сравнении релевантности страницы с конкурентом, но в Гугле ?
Сомневаюсь, что так