
Посмотрел свежие доклады сотрудников Яндекса – со встречи в Минске 16 мая, чтобы зафиксировать самые важные и интересные моменты.
Тысяча и один фактор ранжирования
Тимофей Хаткевич, руководитель группы разработки факторов.
В начале речь идет о довольно хорошо известных вещах. Впечатлил объем работы, которую делают асессоры для выкатки нового алгоритма:
Порядка 10 в 7 степени оценок используется для обучения продакшен-алгоритмов.
Асессор делает одно задание по разметке за 15 секунд. Чтобы оценить такое количество пар ему потребуется 5 лет непрерывного труда.
Еще из вводной части зацепился за NDCG – метрику, которую пытаются оптимизировать в ходе обучения алгоритма. NDCG указана вместе с хорошо известным сеошникам pFound. Встречал раньше упоминания, но никогда серьезно не задумывался что это. Полез гуглить и нашел хорошую статью на русском: https://habrahabr.ru/company/econtenta/blog/303458/, где объяснены термины и дано много полезных ссылок.
Дальше докладчик перешел собственно к факторам.

Особых открытий в этой части нет, но много деталек, которые любопытны нюансами.
- Статические документные – это характеристики документа, которые предпросчитывается и сохраняется в индексах.
- Некоторые факторы относятся к нескольким группам.
- Не каждый клик, сделанный пользователем Яндекса важен или полезен. Перед расчетом факторов клики мы фильтруем специальным секретным алгоритмом антиспама (докладчик многозначительно улыбается).
- Дальше, на 11.30 Тимофей очень понятно объясняет суть TF-IDF.
- Подтверждено, что модификации TF-IDF (например BM25) рассчитываются отдельно по разным зонам документа.
Вообще очень “плотный” доклад, рекомендую смотреть подряд. Больше всего свежих, редко упоминаемых данных касается метафакторов. Процесс ранжирования проходит в несколько этапов. Метафакторы вычисляются на второй и более поздних стадиях, при этом зависят от факторов, которые вычисляются на ранних стадиях.
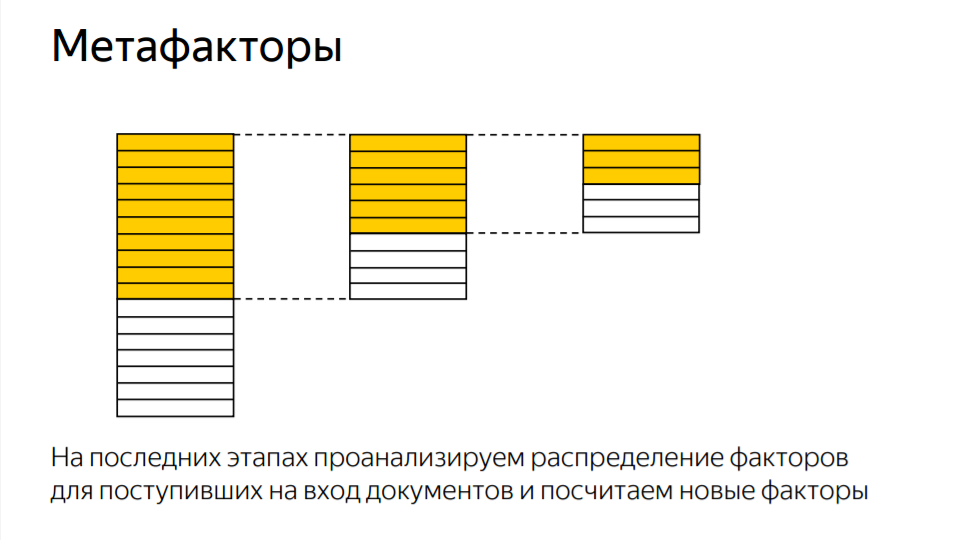
На практике иногда даже такое бывает: фактор на ранней стадии “не жжот”, но когда по нему на последующей стадии посчитать метафактор, это дает дополнительное качество. Мы внедряем некоторые факторы, чтобы по ним посчитать новые факторы.
Чуть-чуть отсебятины: это значит, что при продвижении сложных запросов может иметь смысл не столько копировать характеристики топовых сайтов (бездумное подражание – это вообще сомнительный подход), сколько выделяться на их фоне, чтобы получить хороший рейтинг по метафактору, который “провисает” у конкурентов.
В завершении:
Главные достижения последнего времени относятся к задачам расширения запроса и семантического сопоставления текстов с помощью нейронных сетей.
(об этом следующий доклад).
Из ответов на вопросы:
- Есть факторы, которые мы запоминаем не для всех документов из поисковой базы. То, для каких запоминаем – регулируется тем, насколько документ популярный.
- Алгоритмы, которые использует антиспам, даже внутри Яндекса далеко не всем известны 🙂
Смысловое соответствие текстов в ранжировании
Александр Сафронов, руководитель службы релевантности и лингвистики.
Как обучить машину понимать смысловые связи между текстами?
Расширение запросов
- Морфология
- Синонимия
- Дополнительные слова из документов
“Понимание” морфологии языка – самый простой способ научиться лучше обрабатывать пары запрос-документ без точных вхождений.
Интересный пример со слайда про морфологию:

Докладчик предложил посмотреть, как запрос “сепульковедению” обрабатывают разные поисковые системы. Посмотрим:
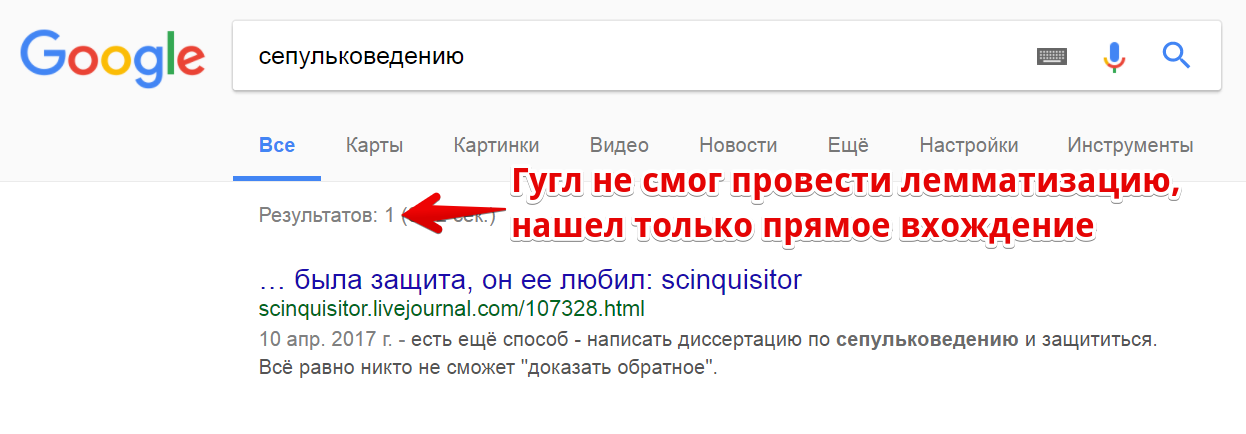
Кстати: лемматизация вообще непростое дело, мои инструменты для работы с контентом, где она необходима (например, анализ встречаемости биграмм в расширенном анализе текста) порой выдают те еще перлы. Ну раз уж и Гугл не всегда может найти корректную начальную форму, то это вполне простительно.
Зато Яндекс справляется с сепульками хорошо:
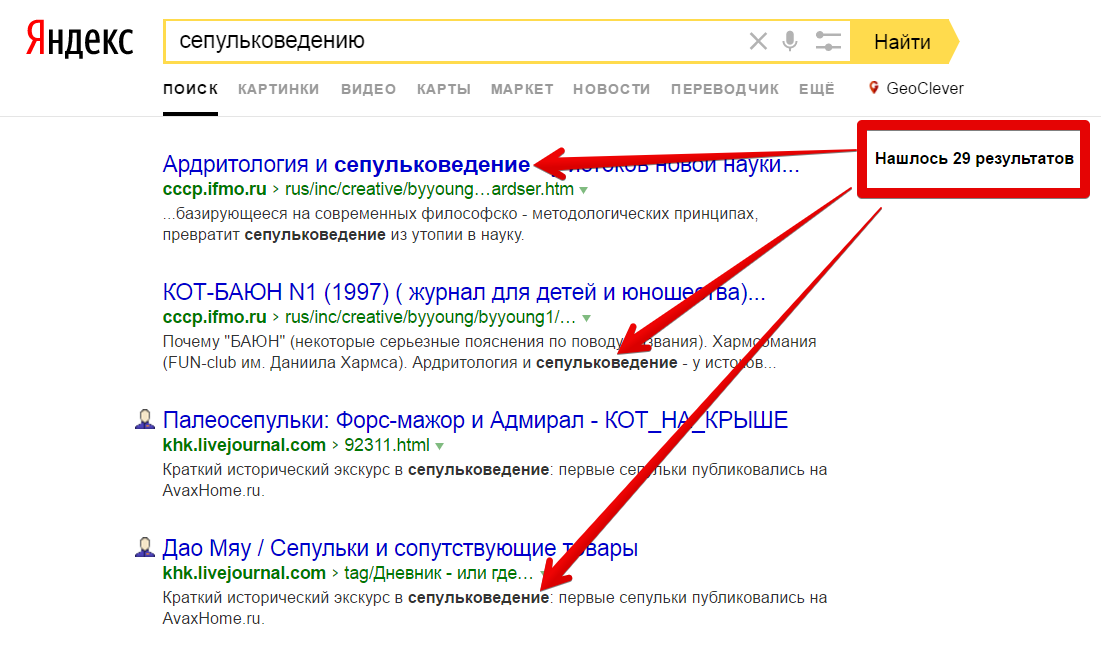
Пара слов или словосочетаний, которая при замене одного на другое не меняет смысл текста – синонимы. Задача более-менее решена.
Александр Сафронов подробнее говорил о пополнении базы синонимов в прошлом своем докладе.

Давайте посмотрим, как люди ведут себя на выдаче. Попробуем найти такие слова для запроса, которые помогают отличить документы по которым чаще кликают от тех, по которым реже кликают по этому запросу. Если слово часто встречается в документах, по которым кликают, это не случайность. Мы можем такие слова выделить.
Документ, который хорошо отвечает на запрос, скорее всего будет содержать такие слова.
Определение похожих запросов также возможно на основе сравнения данных о том, по каким документам кликают по тому и другому запросу. Так можно найти совсем разные по составу лемм, но сходные по интенту ключи:

Тематическое моделирование
Исторически первый метод такого моделирования – LSI. А вообще их очень много:

Вот здесь (28.30) Сафронов делает драматическую паузу и говорит: “Все эти методы объединяет одно общее свойство… они не работают”. Эта часть выступления вызвавала море обсуждений в Фейсбуке – “Как это так, LSI не работает! А мы его используем!”. На самом деле ничего особо нового не сказано. Несколько месяцев назад, разбирая вопрос LSI, я писал:
Если вы внимательно читали предыдущую часть, то могли задаться вопросом — а надо ли вообще этим заморачиваться? Ведь:
- Метод не идеален, имеет множество ограничений.
- Поисковики явно используют куда более сложные алгоритмы.
(Конечный вывод, напомню, был – “так называемые LSI стоит применять, но не для того, чтобы замучить копирайтера требованиями, а чтобы лучше контролировать процесс”).
Главное же не в этом. Доклад был не для сеошников, а для разработчиков. И “не работает” означает “не помогает улучшать качество поиска”. Далее Александр Сафронов рассказывает, почему именно не помогает – а просто потому, что уже накоплен огромный массив “обкатанных” факторов. Опираться чисто на статистику по текстам нет смысла. Ведь в распоряжении Яндекса ценнейшие данные о поведении миллионов пользователей которые эти тексты оценивают, выбирая (или не выбирая) их в выдаче.
Наконец, в сеошной среде под LSI принято понимать в первую очередь тематичные слова, именно их и пытаются добыть SEO-сервисы. А такие очень даже могут повышать релевантность документа запросу (выше прямым текстом сказано о том, что хороший документ содержит слова-расширения).
Нейросетевые модели
Один из динамических факторов (выполняется в ходе запроса). Здесь снова про Палех, без особых новшеств.
Пример оценки релевантности запросу (в квадратных скобках) разных заголовков – по версии BM25 и нейросетевой модели:
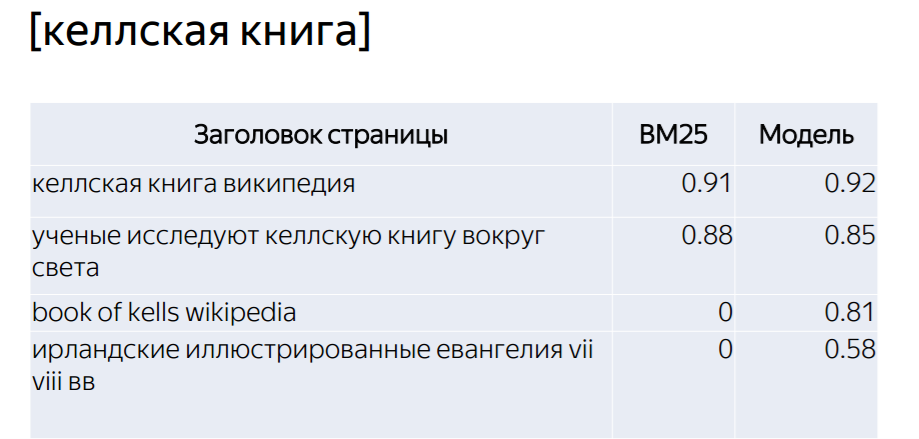
Результаты впечатляющие, но базовые факторы вроде BM25 все равно никуда не делись (и яндексоиды сами это не раз говорили). Кстати, если посмотреть выдачу по этому примеру, то окажется, что большинство заголовков в ТОП-100 имеют точное вхождение:

Так что списывать на свалку старые добрые SEO-правила рановато. Нейросети меняют мир, но совсем не так быстро, как это кажется вдохновенным журналистам.
В ответах на вопросы в основном были уточнения по докладу и не особо интересные сеошникам технические детали (например, на каком железе все это запускается). Единственное – Александр Сафронов отдельно подчеркнул, что данные о поведении пользователей на выдаче очень ценны для поиска, но “конечно, мы смотрим не просто на CTR, там все более сложно и нельзя сказать, что кто-то пойдет покликает и сразу в ТОПе окажется”.
Резюме
- На мой взгляд самая важная часть – про метафакторы.
- Много мелких нюансов про другие факторы (в основном они довольно очевидны, но раньше не имели официального подтверждения).
- Насчет LSI и LDA стало больше ясности в плане отношения Яндекса. Для практики это ничего не меняет. Работаем дальше!



Важно! Что подразумевается под “метафакторы”?
Это факторы, рассчитанные на основе других во время поздних этапов ранжирования. Добавил в пост цитату близкую к тому, что говорил Хаткевич.
Что SEOшникам делать, чтобы улучшить метафакторы?
Смотреть топ, думать, по какому параметру все конкуренты относительно слабы и давить на него. Но это общая идея. На практике может оказаться что слабых мест нет и надо конкурировать в лоб. Ну и вообще тут много вариантов, все зависит от конкретной ситуации.
Формулу кто вывел?
Докладчик 🙂
Спасибо за статью. Не совсем понятно что именно относится к метафакторам. Можете объяснить с примером?
Лучше всего послушать из первых уст – на первом видео, начиная с 12.50
Получается, возможна и обратная ситуация. Два продавлены фактора хороших по отдельности, могут дать метафактор, который даст минус.
Да все ведь просто как 2х2 – делайте сайты для людей 🙂