
В последние пару месяцев писал аудиты и рекомендации по старту для нескольких крупных сайтов (от 200 000 страниц и более). Заниматься такими проектами интересно – поневоле делаешь упор на стратегию, а не на детали. Радует также возможность получить быструю отдачу (недавний пример). Здесь расскажу о ключевых особенностях работы с такими сайтами. Конечно, пост ни в коей мере не является инструкцией (инструкция напоминала бы диссертацию). Это просто памятка для себя, перечисление моментов, которые стоит держать в уме при работе.
Ключевые моменты
Полнота индекса – это важно
Не стоит думать, что у “жирных” сайтов не бывает проблем с индексацией. Поисковые роботы могут буквально не вылезать с сайта, но этого не всегда хватает, чтобы в индексе присутствовали все страницы.
Пример – houzz.ru, представительство гигантского англоязычного сайта с огромной базой и миллионами страниц в Google. А в Яндексе так:
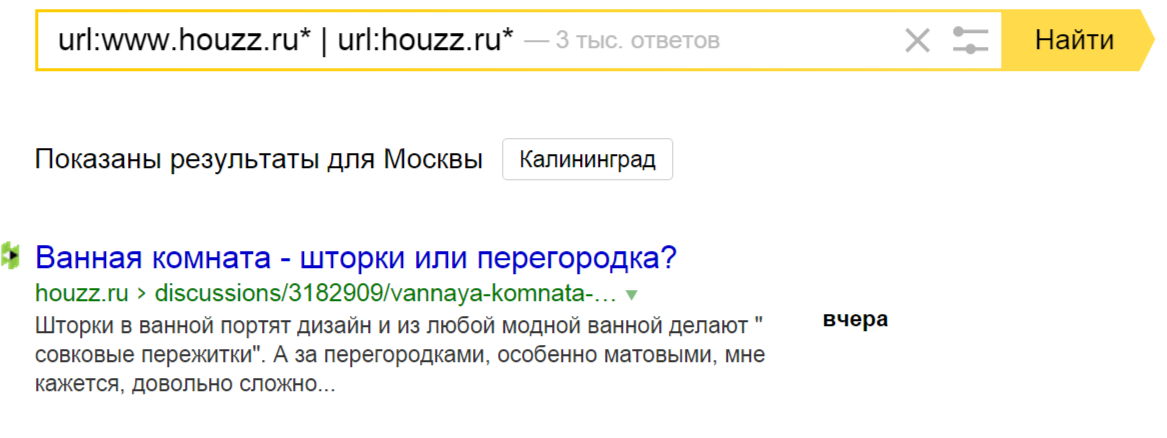
Поэтому первым делом всегда проверяем, соответствует ли индекс реальному количеству страниц на сайте. Если нет – добиваемся, чтобы соответствовал. И регулярно мониторим ситуацию.
Много страниц в индексе – это еще не все
Полная индексация – это только условие получения хорошего трафика, а не самоцель. После полного “загона” в индекс нужно браться за работу с “отстающими” в плане посещаемости разделами. Понятно, что основной трафик будут приносить волшебные 20%, но у остальных, за счет хостовых факторов тоже хороший потенциал, нужно использовать его на полную катушку.
Системы аналитики – твои лучшие друзья
Большой проект хорош тем, что быстро дает достаточно много внутренней статистики (начиная с банальных ключевых слов для расширения семантического ядра и заканчивая сложными закономерностями, связанными с конверсией).
Сайт должен быть “вылизан” с технической стороны
Все просто: небольшая ошибка в одном шаблоне может привести к тиражированию негодных страниц. Единственным неверным движением можно наделать 100 000 полных дублей, например.
Когда у тебя много страниц, всегда можно безнаказанно наделать еще
Один из трендов последних лет – раздувание сайта за счет тегирования. На сайте с небольшим количеством материалов можно внедрить совсем немного тегов и приходится выбирать наиболее важные. Иначе есть риск получить кучу некачественных страниц-тегов. Пока, кстати, за это особо не карают (тсс!), похоже Яндекс борется преимущественно со ссылками и текстовым спамом. Но все может измениться (и изменится, если яростно тегировать начнут и в заштатных SEO-конторах).
Но большим сайтам такие изменения до лампочки: при огромном количестве страниц, минимально грамотная группировка никак не повредит; это – естественный путь облегчения навигации.
И еще страниц!
Для обычного корпоративного сайта попытка наполнить пару новых разделов парсером может приводить к проседанию по главным запросам. А может и не приводить, но в любом случае [неумелая] выгрузка неуникальных материалов это риск. Большому сайту добавление 20 – 30 тысяч неуникальных страниц вряд ли может повредить. А вот пользу принести может, как напрямую – за счет увеличения числа точек входа, так и косвенно, за счет более полного охвата семантики.
Кстати: меня всегда удивляло, почему “парсинг” многие считают синонимом “воровства контента”. Можно добывать контент и не нарушая ничьих прав 😉
Серьезному сайту – серьезную структуру
Структурирование контента еще важнее, чем обычно. Причем как на уровне всего сайта, так и на уровне страницы. Важно создать достаточно много шаблонов страниц с разной структурой и разными механизмами формирования мета-тегов. Второе позволяет, как и в предыдущем пункте, естественным образом увеличить “облако” запросов, которым соответствует сайт за счет переформулировок и синонимов.
Внутренняя перелинковка – это сила
По важным запросам в плане перелинковки можно и нужно работать точечно, не полагаясь на общую ссылочную структуру. Много страниц – много возможностей для нагона веса на важные “узлы”.
Это все, что вспомнил на данный момент. Кто дополнит список в комментах – герой!



К слову о индексации, практически все большие проекты имеют это проблему.
Причина проста – лимиты(квота домена) на краулинг у ботов.
Нет индекса – нет знания о релевантном контенте – нет трафика
Мы как раз будем решать этот вопрос на уровне сервиса.
Думаю одна из ранних фич еще на стадии альфа будет.
Да, причина в лимитах и их бездарном разбазаривании.
Грустно было как то наблюдать когда у сайта 2 700 000 документов, а в индексе не более 1 000 000, понимаешь какая доля трафика просто упускается.
Только если сайт не конкуренту принадлежит. Тогда радостно наблюдать 🙂
ахахах в точку)))
Ага)