
Вряд ли стал писать на эту простую тему, если бы не статья, которая начинается так:
Узнать, сколько страниц было проиндексировано Google, можно с помощью Search Console. Но как отыскать те URL, которые отсутствуют в индексе поисковой системы? Справиться с этой задачей поможет специальный скрипт на Python.
цитата из перевода на searchengines.ru
Вот это да, подумал я. Автор предлагает:
- Установить на компьютер Phyton 3.
- Установить библиотеку BeautifulSoup.
- Установить Tor в качестве прокси-сервера.
- Установить Polipo для преобразования socks-прокси в http-прокси.
- Провести настройки в консоли (не Search Conosole! в терминале операционной системы!).
- Увидеть предупреждение в конце статьи “Если скрипт не работает, то Google, возможно, блокирует Tor. В этом случае используйте свой собственный прокси-сервер”.
- Побиться головой о стену (ой, тут все-таки прорвался мой сарказм).
Как проверять индексацию без лишних мучений?
Автор опирается на верный в основе способ – запросы к выдаче с оператором info:. Это самый надежный метод, но у него есть огромный минус. Один запрос проверяет один url. А что если у нас их 10 000? Или больше?
Очевидно, что нужен более экономный путь. И он есть. Рассказываю.
Во-первых, получаем полный список страниц сайта. Если вы следуете стандартам веб-разработки и минимально заботитесь об индексации, то он должен содержаться в sitemap.xml.
Для удобства работы выгружаем url в виде простого списка. Это можно сделать, открыв xml-файл в Excel:
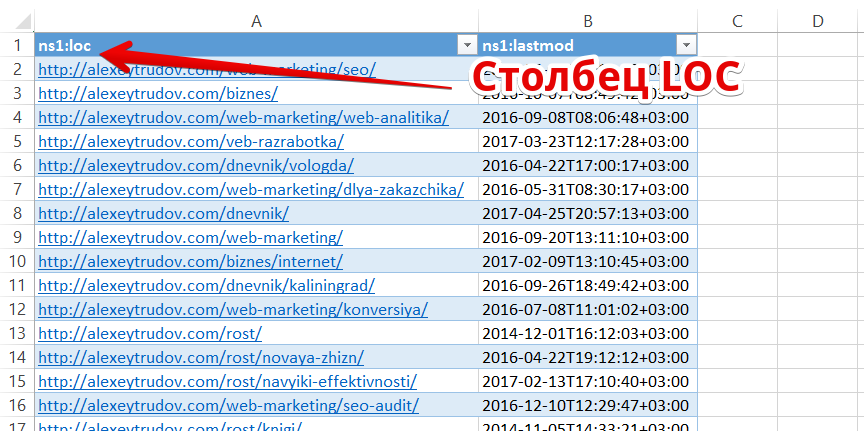
Вся дальнейшая работа сводится к тому, чтобы удалить из списка те страницы, которые есть в индексе.
В посте Как проверить индексацию сайта или раздела в Google? Ответ не так уж прост! я писал о том, что традиционно используемые для пробивки индекса операторы “site:” и “inurl:” не дают точных результатов. Если страница не обнаруживается поиском с оператором, это не значит, что ее нет в базе Googe.
Но! Если уж страница нашлась – это значит, что она в индексе. Понимаете разницу? Оператор находит не все, но уж что находит – то в индексе. Этим и воспользуемся.
Смотрим основные разделы и типичные паттерны в url, формируем список запросов для проверки индекса в них.
Например, для этого блога:
- site:alexeytrudov.com/dnevnik/
- site:alexeytrudov.com/web-marketing/
- site:alexeytrudov.com/veb-razrabotka/
Как быть, если в url нет ЧПУ и явной структуры? Можно придумать много способов. Например, помимо site: указывать фразу, которая есть только в шаблоне определенного раздела. Или наоборот – добавить слово со знаком минус, чтобы найти url, где оно не содержится.
Суть в том, чтобы а) покрыть разные части сайта и б) использовать достаточно сложный запрос, на который Гугл выдаст много результатов (см. предыдущую статью).
Каждый из запросов способен принести нам до 1000 новых url. Нужно выгрузить результаты по ним для сравнения со списком из карты сайта.
Как парсить выдачу?
Способов миллион. Два примера.
Можно воспользоваться Key Collector (куплен у каждого оптимизатора еще в прошлой жизни). Добавляем как фразы запросы с операторами:

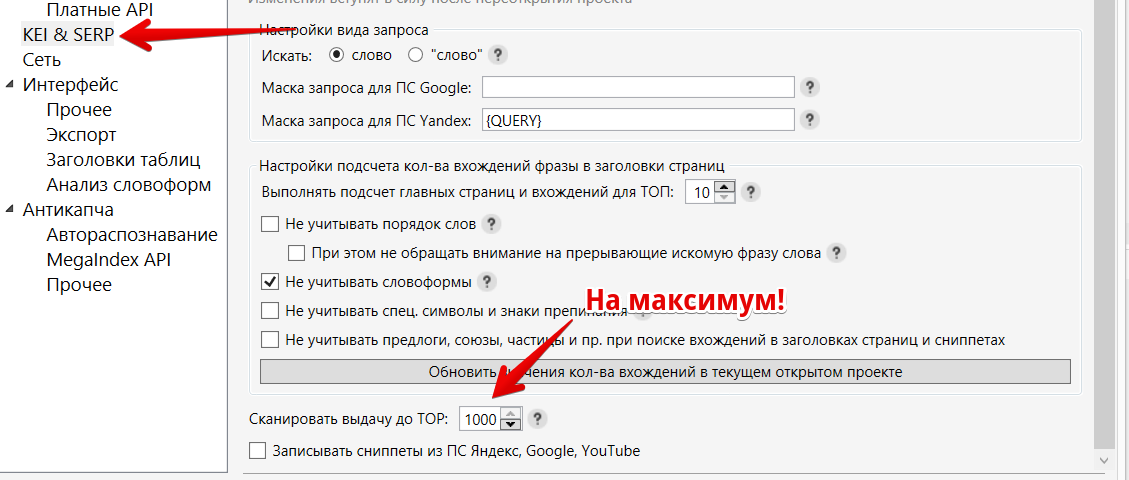
Перед запуском настроим максимальное количество результатов в выдаче:
Теперь сам сбор данных:
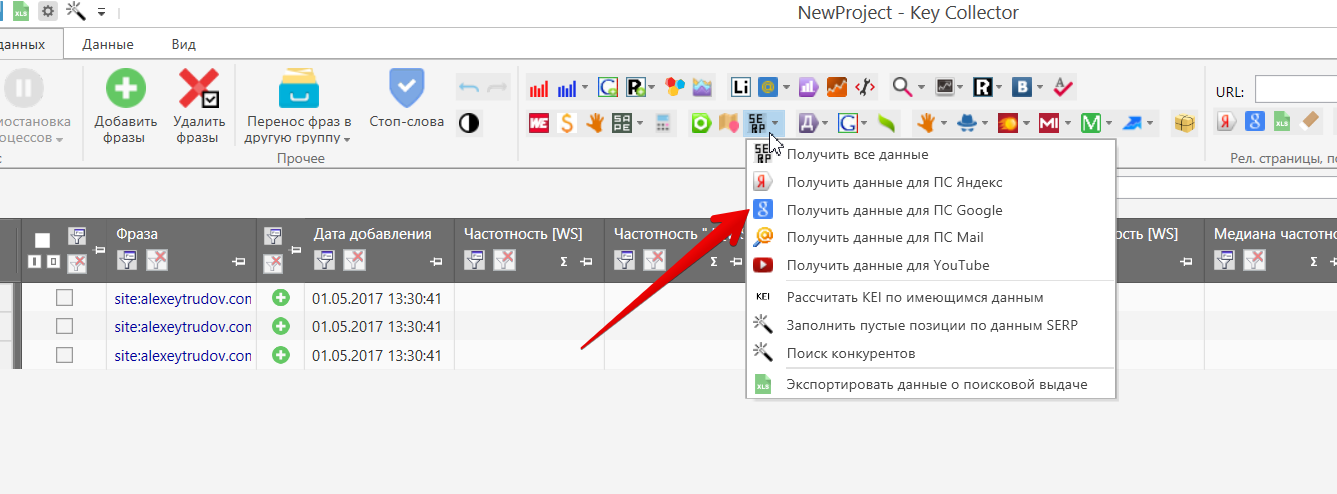
Дожидаемся сбора и выгружаем список url (то же меню, “Экспортировать данные о поисковой выдаче”). Получаем csv-файл со множеством ссылок (у меня на 3 запроса – 136 url, половина сайта, добавив ключи по остальным рубрикам наверняка нашел бы почти все).
Можно ли справиться без Key Collector и вообще без платных программ? Конечно!
- Устанавливаете расширение gInfinity в Chrome (https://chrome.google.com/webstore/detail/ginfinity/dgomfdmdnjbnfhodggijhpbmkgfabcmn).
- Устанавливаете расширение Web Developer (http://chrispederick.com/work/web-developer/) – оно крайне полезно и для других нужд.
Первый плагин нам позволяет загружать в выдаче Google больше 100 результатов простой прокруткой.

Для формирования перечня ссылок нажимаем на значок Web Developer:
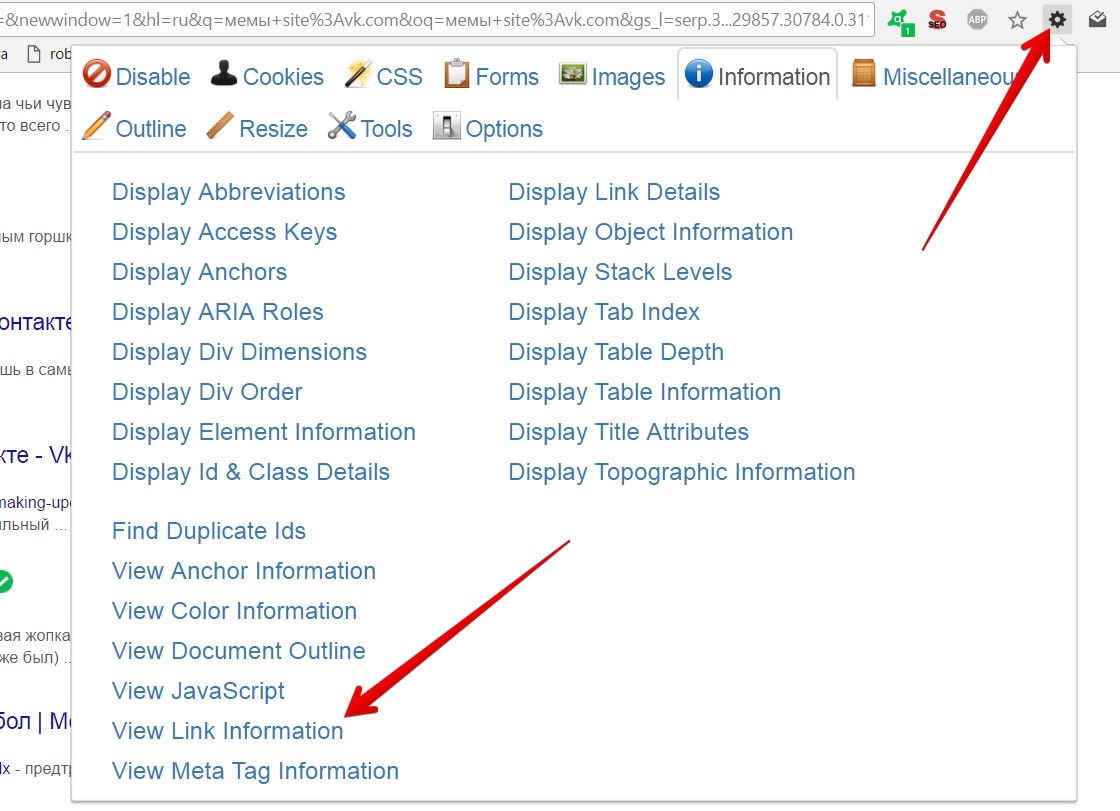
Запрос – зажатая кнопка PageDown – выгрузка.
Теперь нам остается только сравнить списки и вычленить url, которые есть в карте, но отсутствуют в выгрузках из выдачи.
Для сравнения можно использовать бесплатный онлайн-сервис: https://bez-bubna.com/free/compare.php (ну или Excel). Заодно, кстати, не помешает найти страницы, которые есть в выдаче и отсутствуют в карте сайта. Это признак либо неполной карты, либо генерации “мусорных” документов и неправильных настроек индексации.
Если вы корректно подобрали запросы, то наверняка нашли 90% проиндексированных url и сильно сократили объем работы. С оставшимися можно разобраться с помощью оператора info. Разумеется, не стоит это делать руками – можно использовать Rush Analytics. Анализ 100 ссылок будет стоить 5 рублей. Благодаря предыдущим операциям мы существенно экономим. Или можно собрать выдачу тем же Кейколлектором (тут уже правда уже может потребоваться антикапча).
Если хотите еще сократить список кандидатов на платную проверку, то можете также определить список страниц, приносивших трафик за последнюю неделю-две (уж они-то почти наверняка в индексе!) и отсеять найденные. О том, как выгружать url точек входа см. в статье об анализе страниц, потерявших трафик.
Как видите, с задачей поиска непроиндексированных страниц у небольших и средних (где-нибудь до 50 тысяч страниц) вполне можно справиться без возни с консолью, прокси, phyton-библиотеками и так далее. Достаточно иметь под рукой популярные инструменты, пригодные для множества других задач.
UPD: Виталий Шаповал резонно заметил, что:
Наверняка, есть публичный индекс и его непубличная часть, поэтому “непроиндексированные Google страницы” является терминологией вводящей в заблуждение. Корректно говорить об отсутствии в индексе, что меняет постановку вопроса почему такие страницы отсутствуют.
Согласен с этим уточнением; использовал термин из исходной статьи по инерции. Впрочем для практики разница небольшая – так или иначе результирующий список url требуется проработать, рассмотрев разные причины отсутствия (не было визита робота/запрещена индексация/неподходящий контент).



У Шахова есть метод же вроде рабочий
Сканируем сайт пауком
выгружаем в иксель
грузим в кейколлектор как ключи урлы и запускаем яндекс и гугл. смотрим что нашлось, если на 1 месте наш урл – значит проиндексирован
Тоже вариант, но тут опять же число запросов к Гуглу = число url. А парсить выдачу все-таки не так просто, нужно сокращать количество запросов.
Спасибо-) Сколько по времени ушло на все про все?
На пост? Минут сорок
На пробивку индекса по небольшому сайту – минуты четыре.
Comparser?
Компарсер спокойно сканит урлы и показывает отсутствующие страницы в Гугл и Яндексе. Так что есть способ проще.
Спасибо, не приходилось сталкиваться, но взяла на заметку!
Спасибо за статью. Есть также способ с помощью плагина RDSBar, он позволяет парсить ссылки из выдачи одним нажатием быстрых клавиш. К сожалению сейчас Google ограничивает практически любую выдачу 300 результатами. Поэкспериментируйте с любым запросом, любой даже самый популярный запрос ограничен, не говоря уже о поисковых операторах. Так что большие сайты по узким разделам будет трудно парсить. Но маленькие сайты до 2-3к страниц наверное все еще имеет смысл. Что скажите?
По поводу концовки статьи, на мой взгляд сейчас стоит вопрос не в том, есть ли страница в индексе или нет, а в том есть ли она в поиске, потому как сами поисковые системы говорят: если страница в индексе, это не значит, что он будет в поиске.