
Это традиционная подборка коротких наблюдений, мыслей и объявлений по SEO. Пишу здесь о всем, что привлекло мое внимание за последнее время, но не вылилось в отдельный пост.
Как быстро поисковики реагируют на запрет в robots.txt
Провожу эксперимент, один из этапов которого – полное закрытие сайта в robots.txt. 13 декабря был установлен запрет. Яндекс отреагировал очень быстро:
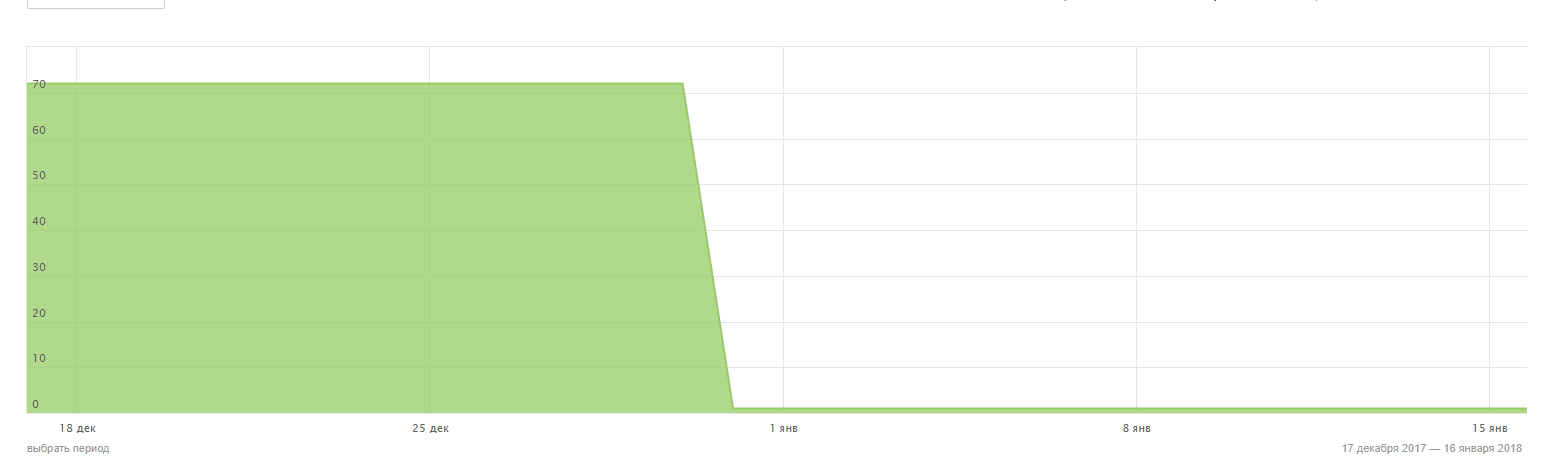
К 30-му декабря были выброшены все страницы, кроме главной.
Google:
- 16 января еще 41 страница ищется через оператор site: (стоит иметь в виду, что зачастую через оператор находятся далеко не все страницы в базе Google).
- 1 февраля через site: ищется одна страница (не главная) в основных результатах и еще 21 в скрытых. Для первой страницы до сих пор отображается корректный сниппет.
Таким образом, еще раз подтвердилось наблюдение, что Google учитывает изменения в robots.txt очень медленно или даже игнорирует. Не говоря уж о том, что зарубежный поисковик вообще рассматривает robots.txt как управление сканированием, а не индексацией (см. подробнее).
Как Google пытается искать по смыслу
Давно известно, что у Google есть система RankBrain, которая призвана находить релевантные страницы, даже если они не содержат вхождений ключевого слова. Отсюда, в том числе, пошла мода на “LSI-копирайтинг”. На днях заметил любопытное проявление этой стороны поискового алгоритма.

Страница была выловлена из обычной выдачи по запросу в виде домена моего блога. С оператором site: она снова ищется. Притом что никакого упоминания моего сайта на сайте Киберленинки нет.
Вот так будет наглядно:

(запрос – alexeytrudov.com + название статьи)
И наконец:
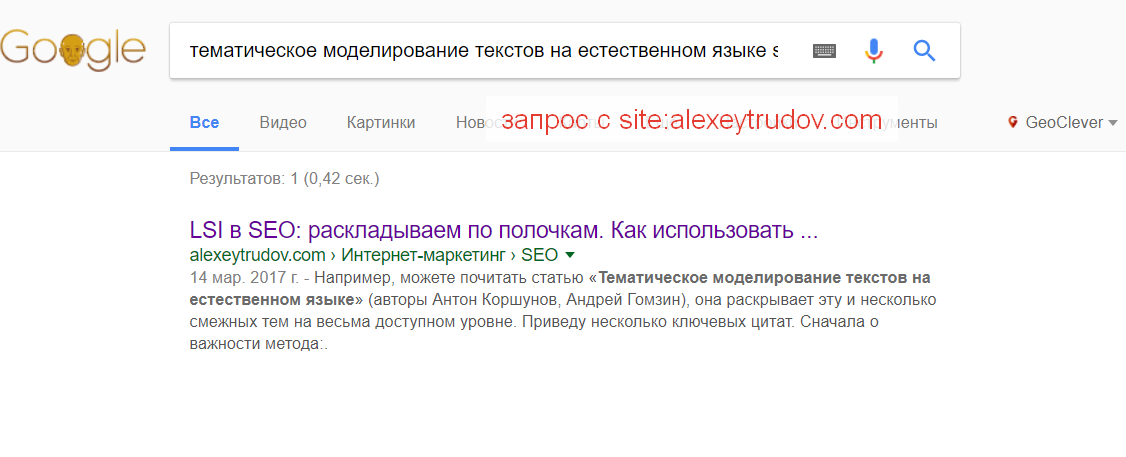
Что мы имеем?
- В статье про LSI (вот это совпадение!) я цитирую публикацию “Тематическое моделирование текстов на естественном языке”.
- А потом эта публикация ищется по моему домену – без каких-либо других сингалов для ранжирования (по крайней мере, я не нашел, за исключением упоминания Киберленинки в другой статье; если кто-то заметит – напишите мне, пожалуйста).
Видимо, RankBrain так и работает – похожая семантика страницы “подклеивают” некоторые слова друг к другу (в данном случае – относительно “чистый”, имеющий мало контекста термин в виде домена к словам из title). Я встречал довольно много похожих примеров, но этот едва ли не самый явный.
Зачем вообще об этом знать? Во-первых, полезно представлять, что творится в черном ящике поисковой системы (это помогает делать более достоверные предположения по аналогии). Во-вторых, есть и чисто практические приложения. Приведу один пример.
Как получить внешнюю ссылку за 10 минут?
На канале Маркетинг сайта (https://t.me/mflow) выложили полезный хак для линкбилдинга:
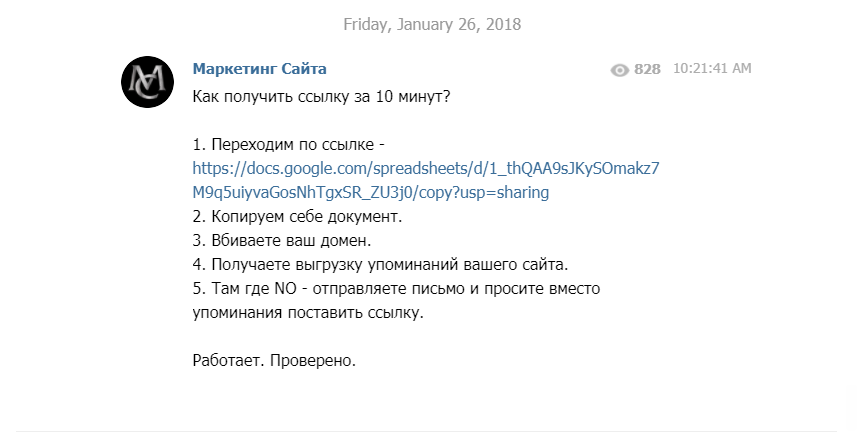
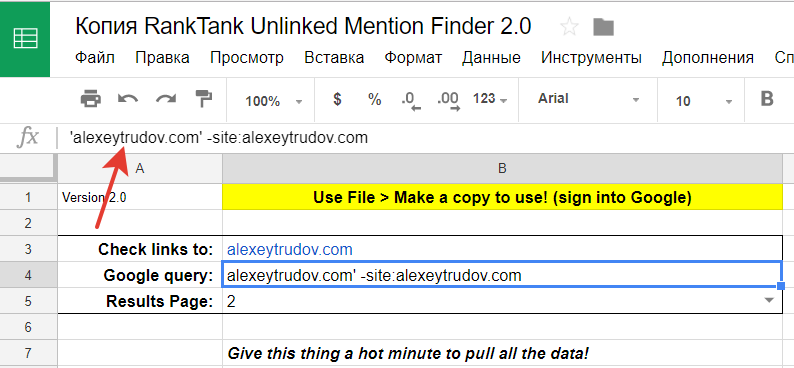
Приводится ссылка на документ Google, автоматизирующий работу – RankTank Unlinked Mention Finder 2.0 (открыть).
Если ничего не менять в шаблоне, то для некоторых доменов можно получить много мусорных результатов. Чтобы не тратить время на их фильтрацию – нужно запретить Google искать по своей логике и заставить его вернуться к точным вхождениям. Поэтому заключаем запрос – бренд нашего сайта – в кавычки:
Насколько актуален “прямой эфир” Яндекса?
Продолжая разбирать Телеграм. Вот вчерашний вопрос в SEO-чате:

Я повозился немного с этой выгрузкой в прошлом году. Ключи, действительно, постоянно повторяются. За вечер интенсивного парсинга удалось собрать всего 155 000 разных запросов. Но важнее другое. Посмотрим, как часто встречаются вхождения номера года:
- 2015 – 3771 запрос.
- 2016 – 705 запросов.
- 2017 – 10 запросов.
Самые частые фразы с вхождением “2016”:
Похоже, что по кругу ходит ограниченная выборка запросов осени 2015 года. А жаль – был бы великолепный источник данных для оперативной ловли трендов в поиске.
Конференция SEMPRO-2018 со скидкой 20%
Анонс для сеошников и вебмастеров, которые ориентированы на буржуйнет.
16 марта состоится очередная конференция SEMPRO. Я был на ней в 2017, мероприятие понравилось (статья по итогам в блоге, отзыв в FB). Судя по отличному набору спикеров, в этом году будет не хуже.
Сам буду смотреть онлайн-трансляцию (лень ехать). Впрочем, можете еще и передумаю до марта, так как побывать снова на афтепати хочется не меньше, чем прослушать доклады.
Для читателей блога есть скидка 20% по промокоду TRUDOV.
Сайт конференции: http://sempro.com.ua/
Новые форматы и цены для консалтинга по SEO
Объявление для клиентов.
Как и планировал, подводя итоги 2017 – изменил подход к консультациям и аудитам. Теперь вообще не делаю базовый технический аудит. Только самый полный вариант (наподобие того, что описан в моем руководстве) либо наоборот экспресс-анализ (с фокусом на важные проблемы и пути развития, а не технические мелочи).
Добавил парочку новых вариантов сотрудничества: анализ коммерческих предложений от SEO-компаний и изучение специфики ниши.
Цены в среднем стали выше. Причина не только в естественной жадности, но и в желании снизить спрос, освободить время. На 2018-й у меня много планов, плюс есть старые постоянные клиенты. Не сильно расстроюсь, если новых заказов не будет вообще.
Актуальные условия и ответы на частые вопросы тут: http://optimumprofit.ru/
На сегодня все. Предыдущие выпуски заметок: первый, второй. Оставайтесь на связи!



шустрые стали поисковики)))
По запрету индексации тоже проводил эксперимент на 2-х сайтах sosnovskij.ru/kak-bystro-udalit-sajt-iz-indeksa/ . Выводы примерно такие же. В итоге самый универсальный метод запрета meta name=”robots” .
Да, тенденция вполне отчетливая. По ряду других сайтов тоже похожие наблюдения (там не замерял тщательно, но пофигизм Google по отношению к robots настолько велик, что нельзя не заметить).