
Получаю много вопросов к посту про алгоритм Google Fred. Главным образом – о том, как технически реализовать закрытие недостаточно качественных страниц.
Небольшая ремарка
Вообще-то самый правильный вопрос – не “как закрыть”, а “как понять, какие страницы достойные, а какие нет”.
Я уже начинаю привыкать к тому, что из любого моего исследования пытаются сделать простую инструкцию на все случаи жизни (еще пример).
Нагрянул Фред? Ну, закроем от Гугла страницы, которые не дают трафика, как Трудов пишет и всего-то делов.
На всякий случай ответственно заявляю: я такого никому не советовал. Наоборот, всегда нужно подходить к проблеме аккуратно, чтобы ее лечением не наделать еще больших неприятностей. О правильной тактике борьбы с Fred-ом тоже как-нибудь напишу. Но сегодня у нас уже почти пятница, поэтому разберем вопрос попроще.
Чем вообще можно закрыть страницы от индексации поисковыми системами?
Традиционно используются либо robots.txt, либо мета-тег noindex. За подробной матчастью отправляю к справке поисковых систем:
https://yandex.ru/support/webmaster/recommendations/indexing.xml
https://support.google.com/webmasters/topic/4598466
Нас же интересует один часто игнорируемый нюанс. Как минимум для Google мета-тег и директива в robots.txt неравнозначны. Robots.txt – это всего лишь рекомендация, не обязательная к выполнению.
Недостатки robots.txt
Вот цитата из официального руководства:
Изменяя файл robots.txt, не забывайте о связанных с этим методом рисках. Иногда для запрета индексирования определенных URL лучше применять другие методы.
(…)
Googlebot не будет напрямую индексировать содержимое, указанное в файле robots.txt, однако сможет найти эти страницы по ссылкам с других сайтов. Таким образом, URL, а также другие общедоступные сведения, например текст ссылок на сайт, могут появиться в результатах поиска Google. Чтобы полностью исключить появление URL в результатах поиска Google, используйте другие способы: парольную защиту файлов на сервере или метатеги с директивами по индексированию.
Robots.txt плох еще и тем, что в нем нельзя указать правило, аналогичное “noindex,follow” (не добавлять в поисковую базу документ, но переходить по ссылкам), что является, например, неплохим универсальным решением для страниц пагинации.
Meta robots – тоже не идеал
Вообще-то meta name robots – отличное решение. Недостаток только один. Иногда, на проектах с кривым движком или ленивым программистом, добиться установки мета-тега на жалкой сотне документов не так-то просто. Что делать, если запрет нужно поставить вот прямо сейчас (а лучше – вчера)?
Заголовок X-Robots-Tag – альтернатива перелопачиванию кода страниц
Есть еще один способ передать поисковым системам информацию, аналогичную той, что содержится в мета-теге robots. Это заголовок сервера X-Robots-Tag. С ним вообще забавная история. Почему-то считается, что умение работать с X-Robots-Tag – страшные мистические знания, доступные только супер-сеошникам. В то же время, описание заголовка спокойно лежит все в той же справке Google.
Да и вообще, ничего сложного в X-Robots-Tag нет. Единственное затруднение – в силу малой популярности, для управления им практически нет готовых инструментов. И совершенно напрасно. Ведь X-Robots-Tag объединяет достоинства robots.txt и мета-тега. Он универсален, гибок и управлять им можно без привлечения программиста (соблюдая, конечно же, осторожность).
Вчера я немного покопался в документации .htaccess и соорудил сервис, который позволяет генерировать правила по установке X-Robots-Tag сразу для множества страниц.
Инструмент доступен по адресу: https://bez-bubna.com/free/htaccess.php (бесплатно, без регистрации).
На вход подается список url:
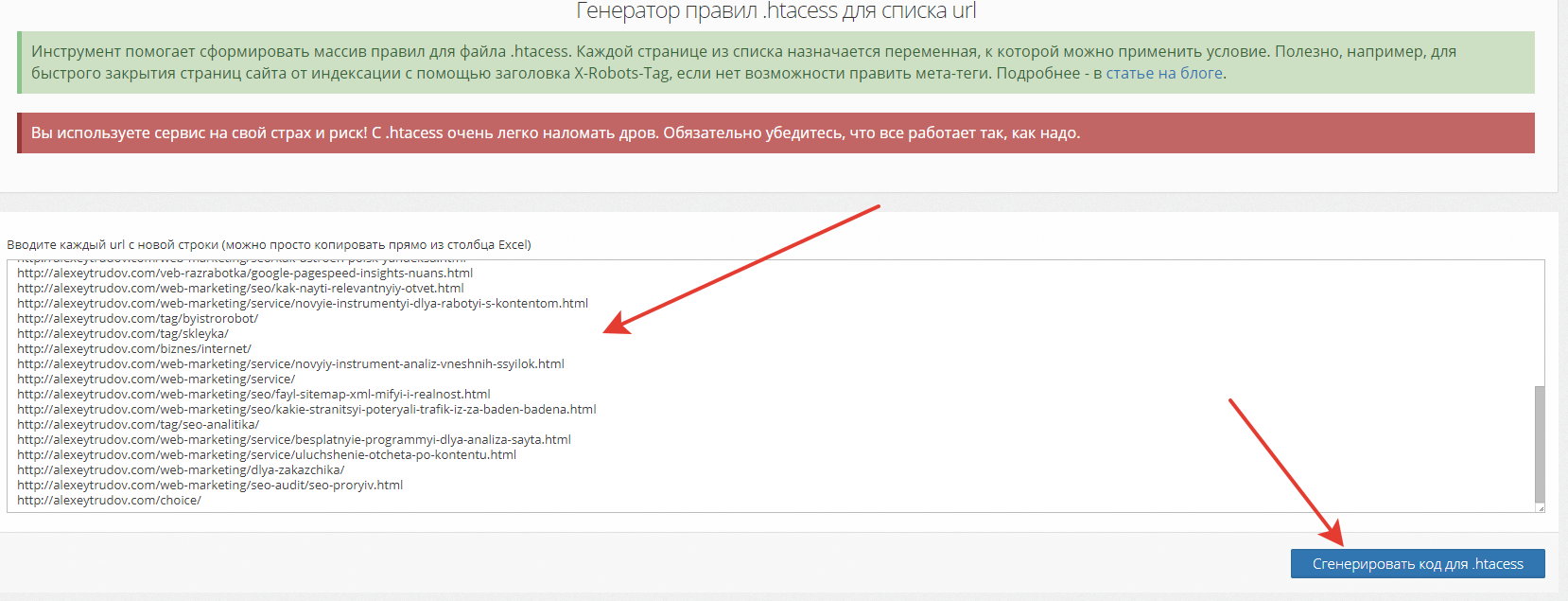
После нажатия кнопочки получаем это:
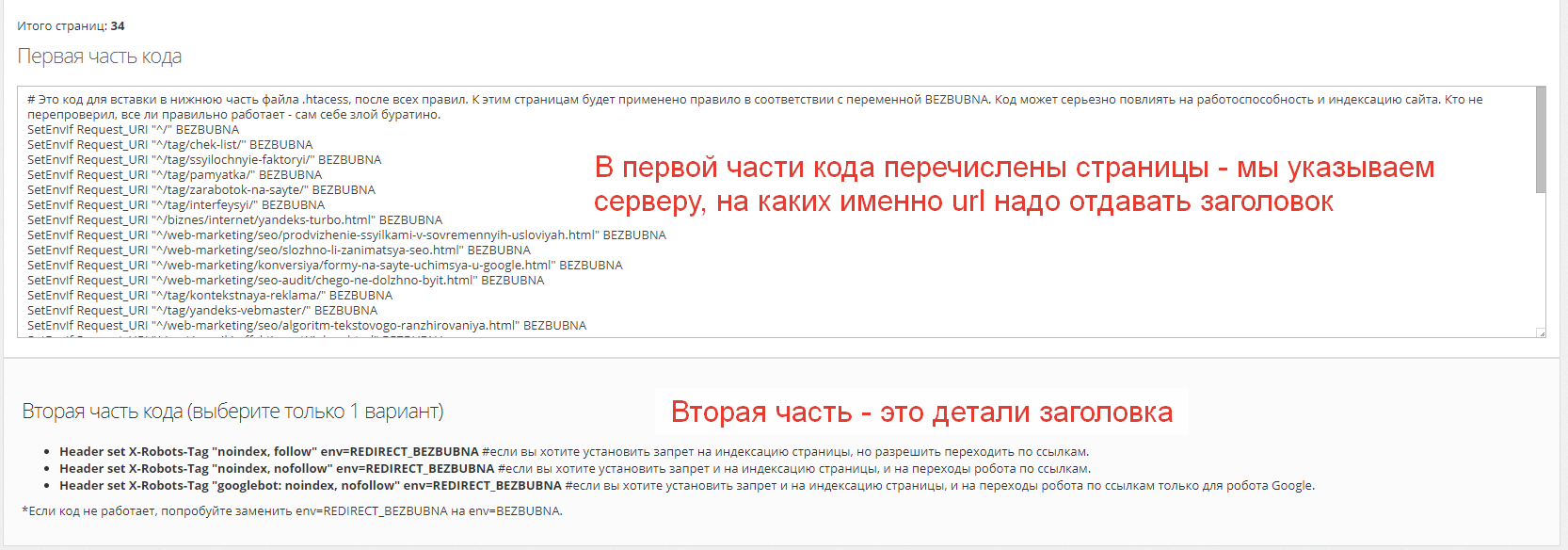
Нам остается скопировать первую часть в конец .htaccess, выбрать один из вариантов второй части (или написать свой) и вставить в тот же файл. Потом обязательно перепроверяем, все ли хорошо работает, не поломался ли сайт от конфликта директив и установился ли заголовок на нужные страницы. Массово это можно сделать с помощью Screaming Frog (раздел Directives).

Ну а проверить конкретный url можно любым детектором заголовков сервера, хоть Вебмастером Яндекса.

В чем минусы?
Если запихнуть в .htaccess очень много страниц, это (теоретически) может сказаться на скорости работы сервера. Я протестировал сайт на 3500 url в .htacess и не заметил снижения скорости.
Первый запуск:

Второй (с разбухшим .htacсess):

Разницы практически нет. Некоторые показатели во втором случае даже чуть лучше (думаю, это погрешность измерений). То есть как минимум до 3500 можно не опасаться проблем со скоростью.
Также непонятна ситуация с поддержкой X-Robots-Tag Яндексом. В справке заголовок не упомянут. Есть сравнительно свежий официальный комментарий в клубе Яндекса:
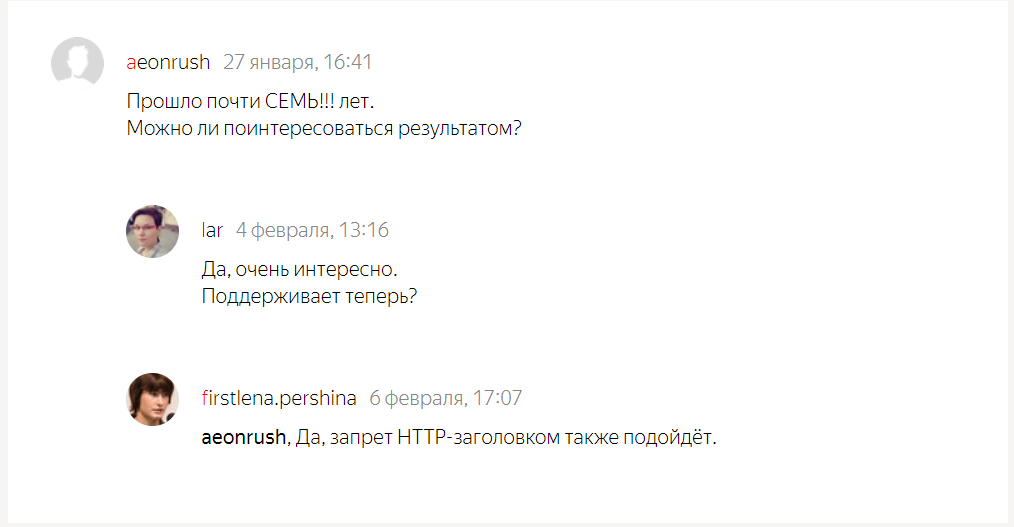
Вроде бы должно работать, но при попытке удалить url, который я 5 минут назад проверил на ответ сервера в Вебмастере, получаю: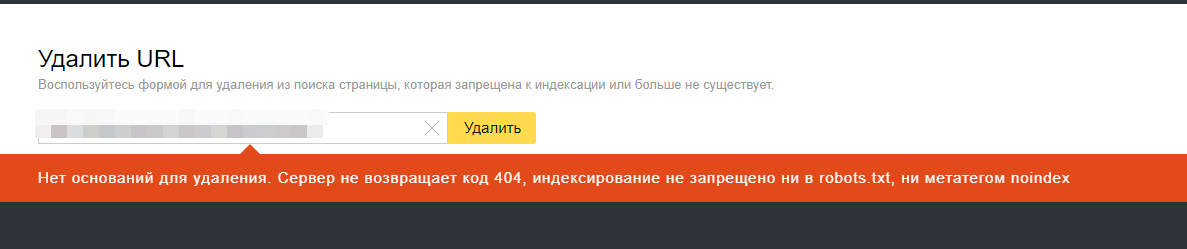
Изучу этот вопрос дополнительно.
В любом случае, для Google способ должен работать. Кстати, есть мнение, что запрет с помощью X-Robots-Tag еще и помогает экономить краулинговый бюджет (ведь роботу не надо скачивать страницу, чтобы добраться до мета-информации). Удачного использования!



Правда, что краулинговый бюджет экономится при настройке заголовка Last-Modified?
Хуже от него точно не будет. Я всегда использую на больших проектах.
Экономится. Причем заметно. На больших проектах это подтверждается 😉
Спасибо за метод!
Как-то раз потребовалось убрать из Google целый сайт (!). Причем для эффективности сразу пошел по нескольким направлениям – настройки сервера с блокировкой ботов, удаление через webmasters tools, robots.txt (а вдруг прорвется, хотя судя по логам – ни разу).
Так вот – удалить что-либо из гугла оказалось адским трудом! Не удаляется и все. Причем сообщает, что “чет на страницу попасть не могу, не?”, “чет у вас каталог / и все лежащие ниже запрещены к индексации. Проверьте!” но даже трафик обрезало неделями. В итоге через примерно два с половиной месяца страниц в индексе поубавилось, но осталось еще море.
Да, есть такое.
За полтора месяца, как я поставил meta noindex для категорий – траф из гугла и яндекса на них не убавился!
Из личного по поисковикам вообще: считаю что нужно делать, особенно на важных проектах, так, как давно известно что это работает. Во всех остальных случаях – скорей всего вы не получите того что хотели, или получите не полностью. Сам влетал, даже после подтверждений каких-то доводов платонами. Сделал вывод, что технические решения должны быть очень простыми и давно известными, иначе роботы надурят ожидания. Этот вывод как-то соотносится с X-robots для Яндекса)
Золотые слова 🙂
Не знал, интересно, спасибо )
Про запрет индексирования страниц в Яндекс
https://yadi.sk/i/sUt0w9a_3PYA76
Одна из страниц, как раз запрещена таким методом X-Robots-Tag: noindex, follow
Идеально подходит для фидов и файлов, когда нужно что бы робот ходил по данным страницам, но не индексировал.
По поводу экономии краулингово бюджета сомневаюсь, нужно проверить это.
Так же как и метатег
По крайней мере Яндекс на моём сайте такие страницы периодически обходит.
Вадим, спасибо за дополнение!
Здравствуйте, благодарю за очень полезную статью, но у меня есть вопрос…
я уже длительное время не могу понять как мне убрать из выдачи ссылки содержащие в себе знак вопроса, что я уже только в роботс не пихаю, гугл нет-нет да что-то все равно закинет в выдачу (( в роботсе у меня следующие строки имеются:
Disallow: /*?*
Disallow: /*?
Disallow: /*?a=
Вопрос: как можно с помощью X-Robots-Tag задать диапазон страниц у которых необходимо выдавать нужный мне заголовок?
Стас, добиться удаления через robots.txt не получится (см. статью). По X-Robots-Tag сходу не подскажу, т.к. не решал такую задачу, тут лучше спросить серверного разработчика (.htaccess стоит трогать только когда на 100% уверен). Но вообще, раз дело касается url с простым шаблоном, то гораздо проще и безопаснее делать это на уровне движка сайта. Код достаточно простой – стандартно проверили вхождение знака вопроса, если он есть – выдаем запрет через noindex,follow (можно и обычным meta robots).
Алексей, благодарю за оперативный ответ, так и поступлю!
Закрыть штатными средствами страницы от индексации в Google невозможно.
Любая страница которая может быть просмотрена анонимным посетителем, будет скачана и Google не смотря на все запреты в robots.txt или meta noindex.
robots.txt и мета noindex это принципиально разные вещи.
robotx.txt это описание предпочтений вебмастера относительно того, что не стоит краулить боту. Подчеркиваю – краулить. То есть скачивать. Не индексировать не ранжировать, а именно краулить.
Гарантировано игнорируется при формировании внешнего ссылочного профиля. Одной внешней ссылки достаточно чтобы бот проигнорировал страницу закрытую правилом в robots и показал ее в выдаче. Что отмечено и в официальной документации.
noindex как часть мета тега так и как заголовок http ответа – это пояснение боту от вебмастера, что эта страница не желательна в поисковой выдаче. Подчеркиваю – страница будет проиндексирована, и может оказывать влияние на весь проект в целом, но она вероятнее всего будет исключена из выдачи.
Проверяется все это на основе очень просто
покупаем новый домен. Создаем три страницы с синтетическим контентом:
A ссылается на B
B ссылается на C
страница B закрыта всеми вариантами noindex.
Открываем логи веб сервера и просим бота проиндексировать страницу A. Наблюдаем как посетив страницу B бот посетит и страницу C, ссылка на которой содержится к якобы закрытой странице от индекса.
Простое правило.
Если что-то нужно закрыть от индексации ботом, это что-то не должно быть ему доступным для скачивания.
Спасибо за подробный интересный комментарий. Я пишу о запрете индексирования в соответствии со справкой Google. В то же время, конечно, путаницы, которая окружает термин “индексирование” предостаточно. Единой терминологии нет. Более того, нет даже принятого всеми достаточного критерия нахождения страницы в поиске (см. тут). А еще до кучи Bing у себя в консоли использует другую терминологию 🙂
Не совсем понял, что это доказывает. Noindex же не запрещает роботу переходить по ссылкам. Для этого есть nofollow. Вот если удастся поставить чистый эксперимент, который доказывает что Google игнорирует nofollow – это будет небольшая сенсация 🙂
По поводу же ссылок с закрытых страниц – ничего странного, Яндекс например их запросто в панели у себя показывает.
Абсолютно согласен.