
Rush Analytics – это онлайн-сервис для SEO-аналитики и сбора семантического ядра. Не буду переписывать инструкции; речь пойдет в первую очередь о впечатлениях от использования. А в конце статьи поделюсь результатами эксперимента по оценке качества кластеризации. Что касается основ работы с сервисом, то все крайне доступно изложено в FAQ. Там же размещен ряд статей, которые интересы и сами по себе, без привязки к Rush Analytics.
Все скриншоты в статье кликабельны.
Первые впечатления
Интерфейс очень дружелюбный. Не так много сайтов, знакомство с “потрохами” которых доставляет удовольствие. Здесь же руки сами тянутся потыкать разные кнопочки и поиграться с настройками. К системе быстро привыкаешь.
Некоторые недоделки, впрочем, присутствуют. Например:
На большом рабочем мониторе это не мешает, но на маленьких экранах приходится лишний раз скроллить страницу.
Больше всего на первом этапе смущает указание цен в пересчете на 1 мелкую операцию:

Начинаешь перемножать цены с предполагаемым объемом задачи, потом переводить тысячи копеек в рубли, потом – все то же самое для другой операции… Итоговая цена за готовое ядро или кластеризацию остается непрозрачной.
На самом деле это затруднение пропадает, стоит только запустить первый проект. Новым пользователям выдаются подъемные в размере 200 рублей на баланс, этого хватит на вполне обширные тесты сбора ключевиков и проверки позиций. А главное – система заботливо рассчитывает стоимость каждого проекта:

Так что внезапно опустошить баланс нам не грозит, все списания четко контролируются.
Еще одна интересная особенность – сервис оповещает по e-mail о заходах с “подозрительных ip”, видимо, в случае отличий от ip, с которого была регистрация/последний вход. Полезная фишка, потерять доступ было бы неприятно. До этого сталкивался с подобными письмами разве что у Google.
Теперь – о модулях системы подробнее.
Проверка и мониторинг позиций
Это традиционный инструмент оптимизатора, тут все довольно просто и прозрачно. Сделано качественно, есть куча полезных настроек, например, съем позиций не по календарю, а по апдейтам Яндекса или история сниппетов (если скрестить с информацией о позициях и посетителях в динамике – можно постепенно добиться отличного CTR в выдаче). Удобно следить за позициями группы ключевых слов.
Лично мне крайне важна возможность сделать срез позиций сайта сразу по нескольким регионам.

Нередко делаю анализ ниши интернет-проекта на заказ, в том числе и для сайтов, которые планируют запуститься на всю Россию. Инструмент нужен, например, чтобы быстро “прощупать” успешных конкурентов, отследить элементы оптимизации, которые позволяют хорошо ранжироваться в разных городах.
Сбор “облака” запросов, составление семантического ядра
Сервис предоставляет возможность спарсить большую базу реальных ключевиков из Wordstat и поисковых подсказок. Тут особенно порадовал второй инструмент. Используя его, я окончательно осознал “преимущество механического транспорта перед гужевым”, то есть – онлайн-сервисов над десктопным софтом.
В ходе настройки проекта можно сразу указать опции для фильтрации ключевых слов, а не возиться потом с самостоятельной очисткой.

Для проекта, которому требуется расширение семантики, я загрузил в анализатор 68 маркерных ключевиков, соответствующих разделам. Указал в настройках “собирать максимум расширений” (для получения подсказок основной запрос модифицируется с помощью дополнения разными символами – пробелы, цифры, латиница – см. на скрине).
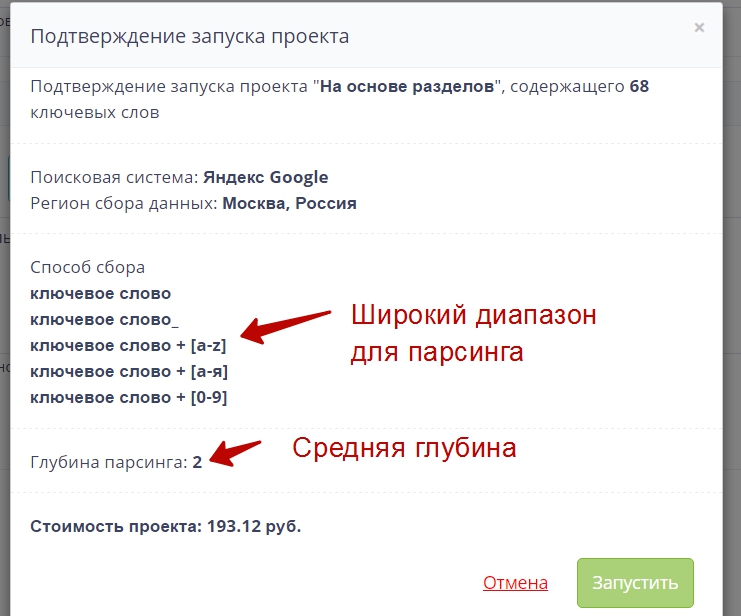
Я поставил проект на выполнение и только отошел налить чаю – дзынь! – мобильник радостно возвестил о новом письме. Rush Analytics прислал отчет о выполнении задания. В итоговом файле было 63 000 ключей. И это стоило меньше, чем бонус за регистрацию.
Скорость приятно удивила, решил для сравнения запустить аналогичный проект на Key Collector. Полноценное соревнование провести не удалось по той простой причине, что парсинг первых 847 подсказок занял почти 11 минут. Быстренько подсчитав, что сбор 60 000 потребует 13 часов работы, я остановил процесс.
Разумеется, если повозиться с настройками, затариться прокси и закинуть несколько баксов на баланс Antigate, можно ускорить процесс сбора и десктопным софтом. Но ввиду отсутствия фильтров по стоп-словам и географии программе пришлось бы спарсить больше, чем 63 000 ключей. А еще это значит, что перед использованием собранные ключи нужно почистить.
Чистка угрожала быть довольно трудоемкой. В моем случае актуален гео-фильтр, требовалось собрать семантику для Москвы. Отбраковка слов с ненужными городами с помощью Key Collector – непростое дело. Городов много, некоторые имеют короткие названия, могут писаться разными способами (Калининград, кгд, Кениг…). Все это надо учесть. А в Rush Analytics условия фильтрации ставятся до запуска в пару кликов – и потом о них можно вообще не думать! Так что мой академический интерес к сравнению скоростей мгновенно угас, и я перешел к следующему модулю.
Кластеризация – делу венец
В модуле кластеризации порадовала возможность выбирать алгоритм: полностью ли доверить формирование групп системе или же указать ручные маркеры. Последнее особенно актуально, например, если есть готовая структура проекта, которую нельзя менять.
В отчетах о кластеризации есть много дополнительных данных, которые будут полезны при создании и размещении контента:
- релевантный url (определяется автоматически на основе выдачи, достаточно ввести домен проекта);
- подсветки (удобно использовать для ТЗ по оптимизации текста);
- эталонный url;
- лидеры тематики.
Претензия к интерфейсу только одна: нельзя задать ручные маркеры к проекту из оценки частотности. Нужно скачивать файл, редактировать его, выставлять нули и единицы. Было бы здорово иметь возможность добавлять два разных файла (в одном – облако запросов, в другом – маркеры) на этапе создания проекта.
Впрочем, это мелочь. Куда важнее, то, что скрыто “под капотом”. Ведь кластеризация – важнейший этап работы с сервисом. Поясню.
Схема работы для разработки детальной стратегии создания или развития проекта такова:
- Собираем облако запросов
- Проверяем частотность
- Смотрим кластеры, строим с учетом дополнительных данных понимаем, что и как должно присутствовать на сайте, чтобы он собирал трафик.
С первыми двумя пунктами все более-менее ясно. Третий же использует довольно сложные алгоритмы. От правильности кластеризации, ее соответствия реальной логике поисковых систем зависит, таким образом, очень много. Можем ли мы в этом доверять системе? Я решил проверить.
Тест качества кластеризации Rush Analytics
Как можно провести более-менее убедительный эксперимент по оценке эффективности кластеризации? Вариант “написать аналогичный сервис и сравнить результаты” отметаем по понятным причинам.
Я решил пойти от обратного:
- Берем список ключевых слов, эффективно распределенный по кластерам.
- Группируем эти ключевики с помощью сервиса.
- Сравниваем первый набор кластеров (эталонный) со вторым (из сервиса), ищем в проверяемом списке ошибки.
Где взять эталонный список? Критерий истины – практика! Нужно просто найти ключевые слова, которые реально приводят трафик на конкретные страницы сайта. Запросы, соответствующие одному url, и образуют кластер.
Ход эксперимента
Я выгрузил из статистики достаточно качественного статейного сайта ключевые слова, по которым пришло больше 50 человек с Яндекса, и соответствующие им страницы входа. Отбраковал пары “ключ – url” с уникальными стартовыми страницами. Таким образом получилось 746 запросов, сгруппированные в 91 кластер размером от 2 до 29 ключей.
Затем загрузил список в Rush Analytics, собрал частотность и отправил на кластеризацию. Выбрал самый грубый метод – просто Wordstat, чтобы не давать системе дополнительных подсказок. Использовал точность 4 (актуальное значение для информационных сайтов).
Сервис отфильтровал 3 дубля и кластеризовал 636 слов (неупорядоченными остались 107 запросов).
Затем я немного повозился и написал php-скрипт, который сравнивает группы по такому алгоритму:
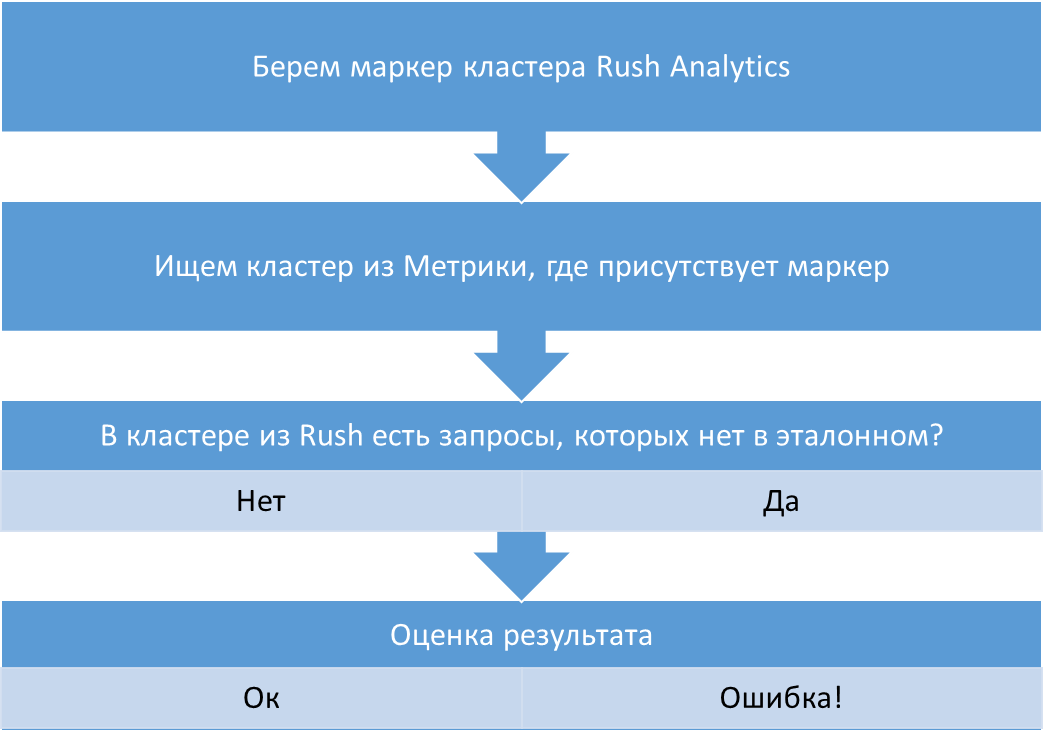
Почему именно такой метод? Потому что наша задача – оценить, насколько хорошо сервис “понимает” разграничение кластеров, не предлагает ли он совместно продвигать запросы, которые на хорошо собирающем трафик сайте распределены по страницам с разным интентом.
Результаты
Основной итог представлен на диаграмме:
Во-первых, результат относится только к тем словам, что удалось кластеризовать. Часть ядра осталась “за бортом”. Однако это не слишком существенная часть. Если, следуя типичному методу работы, использовать на сайте все кластеры + 10 самых частотных необработанных слов, то мы охватим 96% трафика. Как считал: частотность упорядоченных слов – 21645, десятки лучших некластеризованных – 4132, остатка – 994.
Во-вторых, при использовании ручных маркеров, точность, скорее всего, была бы еще выше.
В-третьих, не все случаи, что указаны на диаграмме как ошибки сервиса, являются таковыми на самом деле. По крайней мере часть их связана со структурой сайта. Вот пример:

Возможно, ошибок там вообще нет, просто я не стал вручную анализировать все случаи. Лично мне хватит и 94% точности.
В-четвертых, есть ощущение, что большее количество кластеров в выгрузке из сервиса по сравнению с реальной ситуацией на сайте – вполне адекватно. Сайт, со статистикой которого я работал в этом тесте, достаточно старый и “прокачанный”. Если делать новый – не факт, что он вытянет по 29 запросов на страницу.
Rush Analytics – друг оптимизатора! (вместо заключения)
Сервис понравился не только объективными параметрами вроде удобства, скорости работы и точности результатов. Привлекательна сама идеология проекта:
- Открытость. В большинстве инструментов можно выгрузить/загрузить результаты и исходные данные. Сервис не стремится замкнуть все на себя, никто не запрещает, например, собирать подсказки в Rush Analytics, проверять их частотность каким-нибудь бесплатным инструментом и уже потом запускать кластеризацию.
- Прозрачность работы. Алгоритмы хорошо документированы; прежде чем списать деньги с баланса, система дважды покажет стоимость.
- Результат превосходит ожидания. Например, для меня приятной неожиданностью была подробная дополнительная информация в файле с кластерами. Страница инструмента содержит только то, что нужно для работы и не хвастается богатством данных – это как бы подразумеваются.
Так что если вы еще этого не сделали – регистрируйтесь в Rush Analytics и встраивайте его в свои рабочие схемы, не откладывая. Оно того стоит!



Вы уж извините, но я не смог освоить этот громоздкий и не логичный интерфейс.
А вы пытались? Ребенок разберется.
Автор, а можно нормальную систему комментировать на блоге запилить?
Виталий, какую например?
Хорошая статья.
Сам вот думаю – а нужна ли мне вторая лицензия на кейколлектор, которую купил?
Есть одно но – сервис хорош для сбора семантики, но не подойдет для PPC. То есть, он мусор отминусует, но я мусорные слова не смогу задать в adwords.
Или я что-то не понял?
Спасибо.
Для PPC не пробовал использовать, сложно сказать без практики.
Запустил кластеризацию, сервис висит вторые сутки. При этом деньги списали, а суппорт молчит. Не приятно. Сырой сервис.
Странно, не сталкивался с таким.
Алексей, очень странно. У нас такое технически невозможно и саппорт отвечает в течение часа максимум. Напишите мне на oleg@rush-agency.ru – мы а) вернем деньги б) соберем проект бесплатно в) выдадим вам бонусные деньги
Чем сервис отличается от Semparser’a в плане кластеризации?
А сравнивать реальные данные парсингка КК с сервисом не корректно. Я вот тоже ща в Букварикс волью 63 маркера и посмотрю с какой скоростью он соберет ключи. И не факт, что у сервиса ВСЕ данные ВСЕГДА актуальны, а КК именно свежак выдает.
Насколько я знаю, RA собирает данные не из базы, а непосредственно с выдачи, поэтому на мой взгляд сравнение корректно. Semparser не тестировал
Поправьте или удалите ссылку на 404 страницу http://prntscr.com/gx9l0h
Спасибо!