
Набралась очередная порция коротких наблюдений и мыслей по SEO.
Удаление текста из-за Баден-Бадена и позиции в Google
Распространенная методика борьбы с Баден-Баденом на коммерческих сайтах – простое удаление текста. Едва ли не одновременно с анонсом алгоритма появились кейсы быстрого снятия санкций с помощью тотальной зачистки страницы. При этом позиции в Google не снижались.
Казалось бы, идеальная методика. Но есть два нюанса.
Во-первых, трафик из Яндекса по низкочастотным запросам при удалении текста все равно падает. Да, важные ключи можно упомянуть в title и h1, однако эти теги не резиновые. Вместить все многообразие поисковых фраз из “длинного хвоста” в них невозможно.
Во-вторых, позиции в Google далеко не всегда меняются сразу после правки документа. Неоднократно наблюдал, как очень резкие изменения контента не приводят значимому изменению позиций. Например, так было в эксперименте со скрытым текстом:
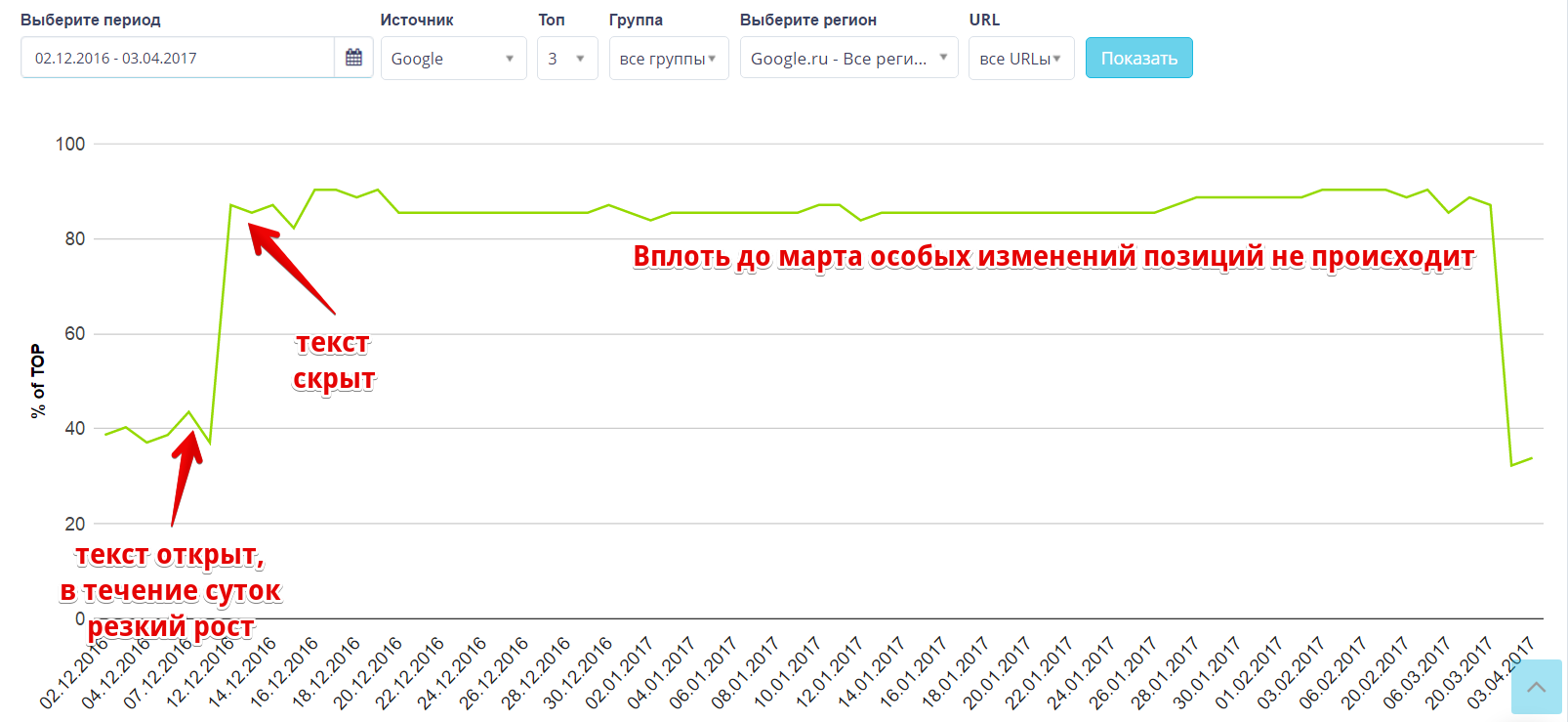
Подробнее см. тут.
То же самое наблюдал на всех старых сайтах из эксперимента с возрастом. Страницы, где полностью поменялся контент и исчезли вхождения, продолжали хорошо ранжироваться по запросам, которые релеванты удаленному содержимому и абсолютно (!) не релевантны новому.
Почему так происходит? Праводоподобная гипотеза, основанная на патентах Google – это сознательное применение поисковиком функции перехода для борьбы с нахальной оптимизацией.
Окончательное значение релевантности присваивается документу не сразу. А в переходном периоде документ ранжируется по особым правилам. Например, с задержкой нарастания релевантности:
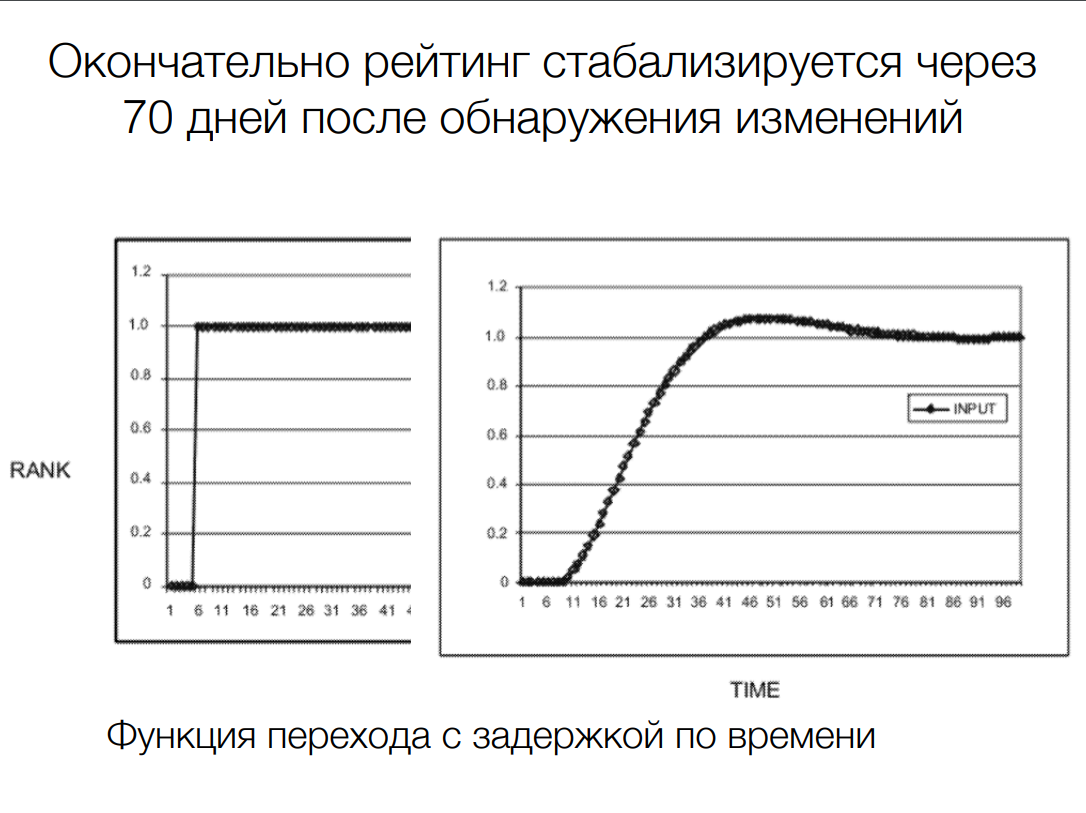
Левый график – изменение релевантности без функции перехода, правый – с ней. Картинка взята из презентации Сергея Кокшарова (рекомендую ознакомиться с его вебинаром на эту тему).
Возвращаясь к Баден-Бадену: видел несколько проектов, которые через некоторое время после снятия санкций начинали терять трафик из Google. Так что стоит быть осторожным с удалением всего текста. Прежде чем рубить текст сплеча, стоит (как минимум) проверить, по каким запросам страница привлекает посетителей. Смотрим Search Console, ищем ключи и их вариации, для которых вхождения есть только в основной контент, но не в title и h1.
Рекомендованные запросы в Яндексе
Недавно в Яндекс.Вебмастере появился раздел “Рекомендованные запросы”. Идея очень полезная. Хотя бы потому, что в нем показываются фразы в связке с релевантными страницами и регионами.
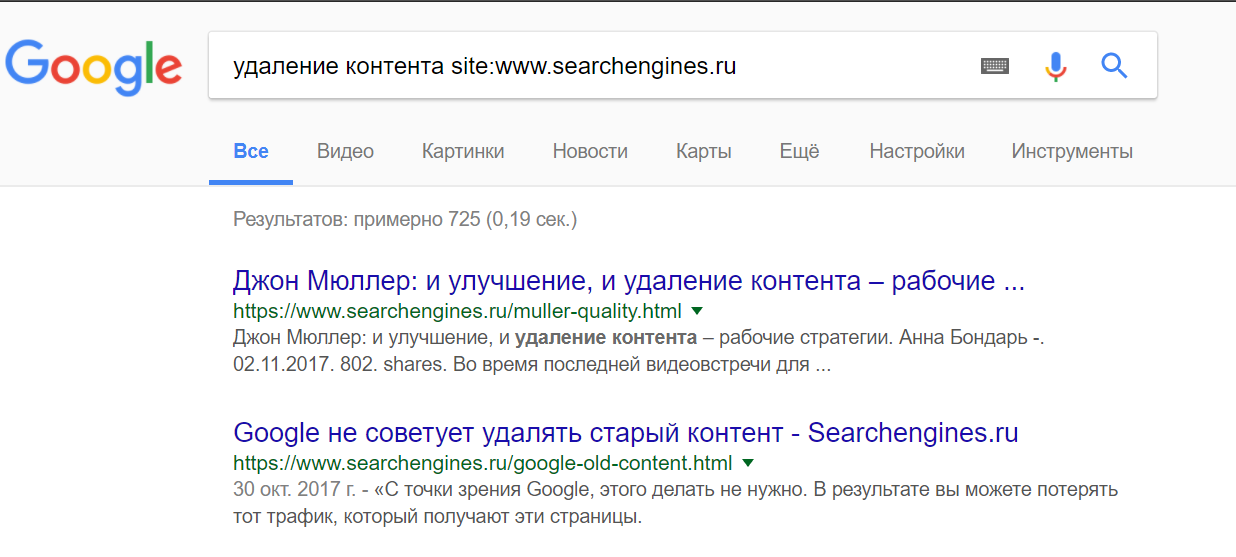
Вчера я рассказывал, почему нельзя полностью доверять методу определения релевантных страниц через оператор “site:”. Вообще-то нетрудно выловить релевантный url и из “большого” поиска, но многие инструменты заточены именно под “site:”. Так что дополнительный (и как бы официальный) взгляд не помешает.
Правда, некоторые вещи в реализации вызывают недоумение. Скриншот для этого блога:
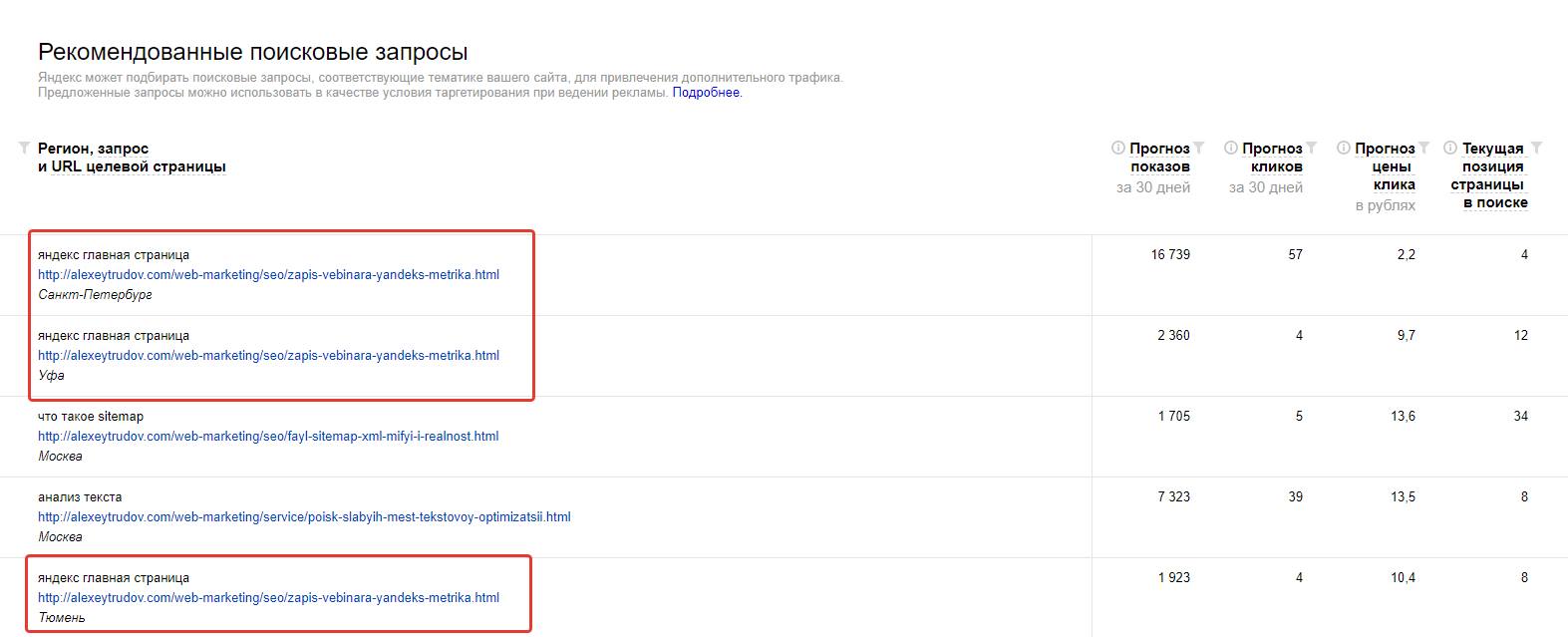
Во-первых, сюда подмешиваются в том числе навигационные запросы, продвигаться по которым не имеет смысла (впрочем, иногда прием “прицепиться к чужому бренду” работает).
Во-вторых, “текущая позиция” определяется довольно странным образом. Вероятно, итоговая оценка позиции формируется с учетом свежести документа (которая быстро меняется). Думаю, эту страницу могло подбросить в ТОП-5 по запросу “яндекс главная страница” разве что попадание в примесь быстроробота.
Canonical и атрибуты next/prev на пагинации
Вообще, в вопросе управления индексацией подстраниц уже сломано столько копий, что хватило бы вооружить десяток легионов. Есть более-менее надежные и универсальные решения, но их многообразие продолжает будоражить умы. Вряд ли стал бы делать эксперимент специально, но получилось практически само по себе.
В конце ноября вдруг обнаружил, что презентации с Google Slides на странице, где я собираю все свои доклады плохо отображаются на мобильном. Перезалил их с помощью WordPress-плагина Embeds – адаптивность появилась, зато страница стала грузиться 15 секунд. Пришлось разбить ее на подстраницы (1 url – одна презентация):

Заодно решил проверить, что будет, если последовать рекомендациям обеих поисковых систем и установить одновременно canonical (для Яндекса) и атрибуты next/prev для Google. Подчеркну, что, согласно Google, использовать так canonical неправильно (не повторяйте на рабочих проектах, если не уверены в том, что делаете!).
На текущий момент, по Вебмастеру видна следующая картина:
- Все url пагинации посещены роботом Яндекса еще 25 ноября.
- В индекс попали страницы сайта, опубликованные позже этой даты.
- Страниц пагинации в индексе нет.
А вот Google повел себя иначе. Страницы в индексе, но по запросу “Презентации с моих докладов и вебинаров” показывается главная страница раздела:
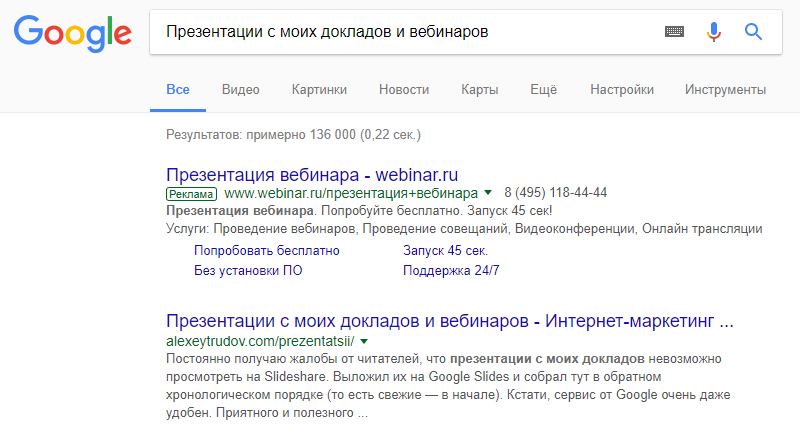
Даже если поискать только по сайту – страницы пагинации не находятся.

Подстраницы по основному запросу можно найти только с операторами расширенного поиска. И то в скрытых результатах:
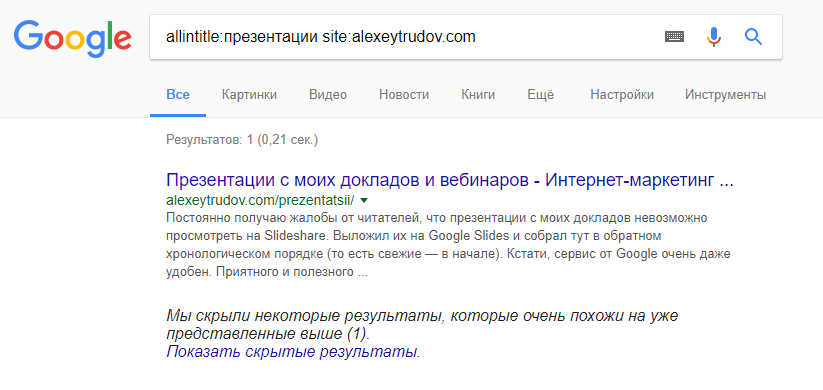
А вот если искать уникальный контент с подстраницы – то она встает в ТОП-1.
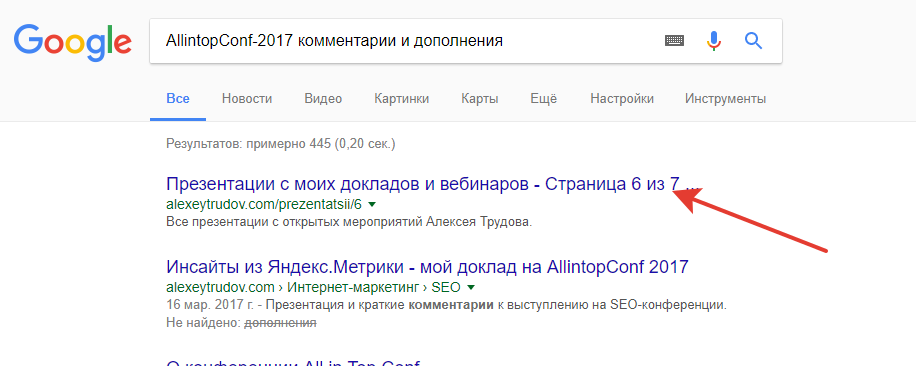
Похоже, что Google достаточно умен, чтобы интерпретировать canonical для страниц с уникальным контентом по-разному на разных запросах. И если использовать его в связке с next/prev – ничего страшного не произойдет. Впрочем, это довольно смелое предположение, есть и другие объяснения.
Если кто-то проверит гипотезу на адекватной выборке – пришлите ссылку, обновлю пост.
Почему внимать откровениям говорящих голов из поисковиков – недостаточно
Обожаю западную SEO-аналитику, построенную вокруг толкования твиттов Гэри Илша. На десерт – объяснение в одном скриншоте, почему это путь в никуда, почему надо смотреть сначала на практику и эксперименты, а только потом на заявления с высоких трибун.
(Да хотя бы потому, что говорящие головы порой не могут договориться между собой!)
p.s. Предыдущий выпуск заметок тут.



У нас при организации пагинации по схеме canonical + next/prev через довольно продолжительное время появились в поиске подстраницы. Анализ по метрике показал, что среди них значительную долю занимают вторая и последняя подстраницы. Самые посещаемые после первой. В качестве гипотезы можно предположить, что это следствие ПФ.
Юлия, спасибо, интересное наблюдение!
Рост мегастремительный)
На мой дилетантский взгляд ничего плохого не заметил в связке canonial и next/prev. Поставил 3 месяца назад и всё ок. Хотя, что должно быть не ок?!)
Google не советует так делать, т.к. canonical нужен для склеивания очень похожего или идентичного контента. Выпускали даже специальные разъяснения что на пагинации так делать не стоит.
Привет, Алексей. Крутой блог.
Скажи, как думаешь, учитывает ли Яндекс биграммы в интернет-магазинах на страницах категорий. Вот допустим есть категория “бетонные покрытия”. И пошли карточки:
Бетонное покрытие “Эльбрус” цена: 1 руб.
Бетонное покрытие “Шмельбрус” цена: 2 руб.
и т.д.
И таких “бетонных покрытий” у нас минимум пол сотни получается на страницу. А потом еще для добивочки seo-текст. Сказка)
А ведь еще эта биграмма в верхнем выпадающем меню, да в боковом, ну и в футере, чтоб не заблудился.
По моим наблюдениям, чем больше повторяется в менюшках всяких, тем меньше нужно вхождений в текст.
Но насколько Яндекс (и Google) жесток по отношению к вхождениям в меню, сайдбар, футер, хлебные крошки. Пока полностью разобраться не удалось.
И сервис твой, понятное дело, показывает разные результаты при обработке только Plain Text, или при парсинге всей страницы за вычетом html, css, script тегов.
Привет! Спасибо!
Поэтому зачастую в SEO-текст вхождения основного ключа и не нужны. Я обычно начинаю с полностью белого и пушистого текста (с добавкой более длинных ключей, чтобы охватить запросы типа “прочное бетонное покрытие” – упоминаю “прочное” в тексте). Если этого оказывается недостаточно – экспериментирую с вхождениями.
Да, очень часто именно так.
Прилететь за них тоже может. Но если реализация не совсем уж спамная – то относятся спокойнее чем к вхождениям в текст.
Все правильно, поэтому его в первую очередь стоит применять для сравнения страниц внутри сайта.
Супер