
Из анонса нового алгоритма Яндекса известно только, что от него могут пострадать страницы с переоптимизированным контентом. В качестве примера приводится анекдотичный фрагмент, где на все лады склоняется ключевик “SEO-текст”. Рабочих способов различить “плохие” и “хорошие” тексты не приводится.
Работать наобум – не наш метод, так что попробуем выделить критерии самостоятельно.
Объект и методика
В первую очередь меня интересовало, при каких условиях санкции накладываются на более-менее приличные страницы, когда вполне можно читать, не морщась в каждом абзаце от корявой оптимизации. Анализ крайних случаев – с сотней вхождений, выделенных жирным – вряд ли принес бы ценные данные, тут и так все ясно.
Исследование опирается на простую идею – сравнить характеристики двух групп страниц одного и того же сайта:
- где наблюдается значительная просадка трафика в момент запуска Баден-Бадена.
- где посещаемость стабильна или выросла.
Благодаря анализу внутри одного хоста мы уравниваем множество факторов и можем быть более уверены в выводах.
Всего удалось собрать 68 сайтов, где трафик с Яндекса существенно просел после 22 марта 2017 (спасибо всем, кто прислал свои проекты на анализ!).
В SEO-исследованиях размер выборки – это своеобразный культ, однако я уверен, что куда важнее ее однородность. Поэтому беспощадно удалял из рассмотрения все, что могло исказить результат.
В частности, я отбраковал сайты:
- С малым количеством посещаемых url (если документ до фильтра приносил менее 100 посетителей в месяц с Яндекса, падение трафика статистически недостоверно).
- Где трафик с Google также имел выраженную тенденцию к снижению.
- С высоким разнообразием контента (тематически или структурно).
- С высокой зависимостью от сезона.
- Где также сработал хостовый фильтр.
- Оптимизированные совсем топорно/не несущие вообще никакой полезной информации (первый критерий был полностью формализован, второй – частично).
Также были вынесены из основного исследования интернет-магазины и сайты услуг (их было меньше в выборке; в отличие от статейных проектов, текст здесь зачастую не играет роли и само его наличие порой говорит о чрезмерной оптимизации).
В итоге остался 31 сайт и 4297 документов для анализа.
Прежде чем перейти к сравнению характеристик успешных и потерявших трафик страниц, необходимо было прояснить еще один важный вопрос.
Баден-Баден – запросный или документный?
Как я писал в недавнем обзоре публикаций по Баден-Бадену, из официальных заявлений следует, что санкции “первой волны” применяются к странице (анонс от 23 марта). Однако многие SEO-специалисты называют Баден-Баден запросозависимым, указывая на то, что позиции сильнее всего просели у ключевых фраз, под которые текст затачивался в первую очередь.
Это не простой спор о терминах, а ключевой момент. Давайте разберемся.
Чем вообще отличаются документный и запросный фактор/фильтр?
(Употреблять “фильтр” по отношению к Баден-Бадену не вполне точно, использую для краткости).
Различие – внутри алгоритмов поисковой системы.
| Запросный | Документный | |
|---|---|---|
| На что влияет | На ранжирование по конкретному запросу/группе | На “общий рейтинг” страницы по всем запросам |
| Пример фактора | Анкорный вес | Статический вес |
Может ли изменение общего рейтинга повлиять на позиции только группы запросов? Сколько угодно! Чтобы было совсем наглядно – еще одна табличка. Допустим, есть три url – A, B, С c определенными значениями релевантности по 3 запросам:
| Ключевые фразы | стр. A | стр. B | C |
| 1 | 0.5 | 0.4 | 0.35 |
| 2 | 0.6 | 0.55 | 0.4 |
| 3 | 0.7 | 0.6 | 0.4 |
Допустим, страница B попала под санкции, ее общий рейтинг оштрафовали на 0.1. Смотрим на релевантность по запросам:
Что произойдет после применения штрафа?
- Первый запрос просядет.
- Второй останется где был.
- Третий останется где был.
А теперь представим, что санкции были наложены одновременно с апдейтом. Причем незадолго до него более успешный конкурент по третьему запросу (страница A) поменял что-то на странице и его релевантность упала до 0.45.
Тогда третий запрос вырастет (0.45 против 0.5).
Вывод? С позициями страницы, которая попала под документный фильтр, может твориться все что угодно (хотя общий тренд, разумеется, к понижению). А ведь это очень упрощенная модель. Не учтен многорукий бандит, возможные технические ошибки при сборе и так далее.
Говорить о том, что фильтр позапросный только на основании разной динамики позиций у ключевых слов страницы нельзя. Это лишь гипотеза.
Проверка гипотезы о запросозависимости
Рассказываю кратко, так как все это по-прежнему преамбула к основному исследованию. Для документов, где было выявлено существенное падение посещаемости вследствие Баден-Бадена:
- Была собрана статистика по ключевым фразам, которые давали трафик за 3 недели до фильтра.
- Фразы были разбиты на 2 группы: а) не содержащие лемм, отсутствующих в тексте б) содержащие леммы, которых нет в тексте.
- Подсчитан трафик для каждой из групп, определена доля в общем трафике.
- Аналогичные подсчеты для трех недель после фильтра.
Как должна измениться доля трафика по ключам из второй группы? Это фразы, прицельная оптимизация под которые не проводилась (иначе был бы задействован самый банальный фактор текстовой релевантности – вхождение всех слов запроса), по которым трафик поступал “естественным образом”.
Если фильтр запросозависимый, то доля трафика по таким ключам должна вырасти: ведь Баден-Бадену их карать не за что.
Что видим в итоге? Картина прямо противоположная:
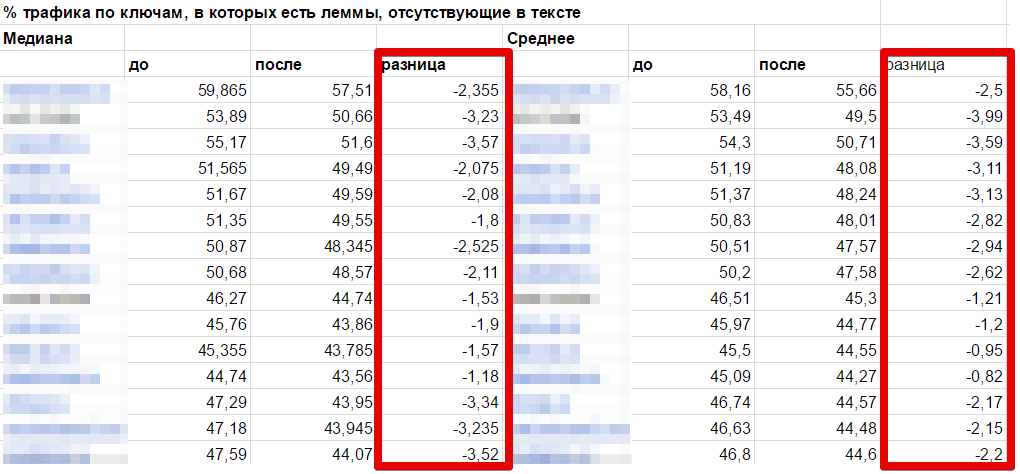
Для всех сайтов выборки (!) и медианное и среднее значение доли трафика по таким ключевым словам снизилось. В среднем на 2,6% – немного, но этого достаточно, чтобы с абсолютной уверенностью заявить, что уж прироста точно нет.
Трафик в данном случае максимально надежный критерий, так как в нем аккумулируется и отражается информация обо всех позициях по всем запросам. А не о паре-тройке десятков, специально отобранных оптимизатором.
Вывод: Баден-Баден проявляет себя как документный фильтр, гипотеза о запросозависимости не подтвердилась.
Не хочу занимать место в статье объяснением, почему уменьшение доли трафика по запросам с отсутствующими леммами – дополнительный аргумент в пользу вывода. Поэтому мини-конкурс: кто лучше всех раскроет этот момент в комментариях – получит 5 проверок на баланс в https://bez-bubna.com/ (а еще славу и уважуху). Дерзайте!
Кстати. Раз алгоритм карает страницы, то делаются совершенно бессмысленными часто встречающиеся заявления вроде “при Баден-Бадене, наложенном на документ, происходит просадка на N позиций”. Мне попадались варианты “7-30”, “20-30”, “10-40”.
Вот результаты понижения на 3 (ну, максимум на 5 – смотря что считать исходной датой) позиций:
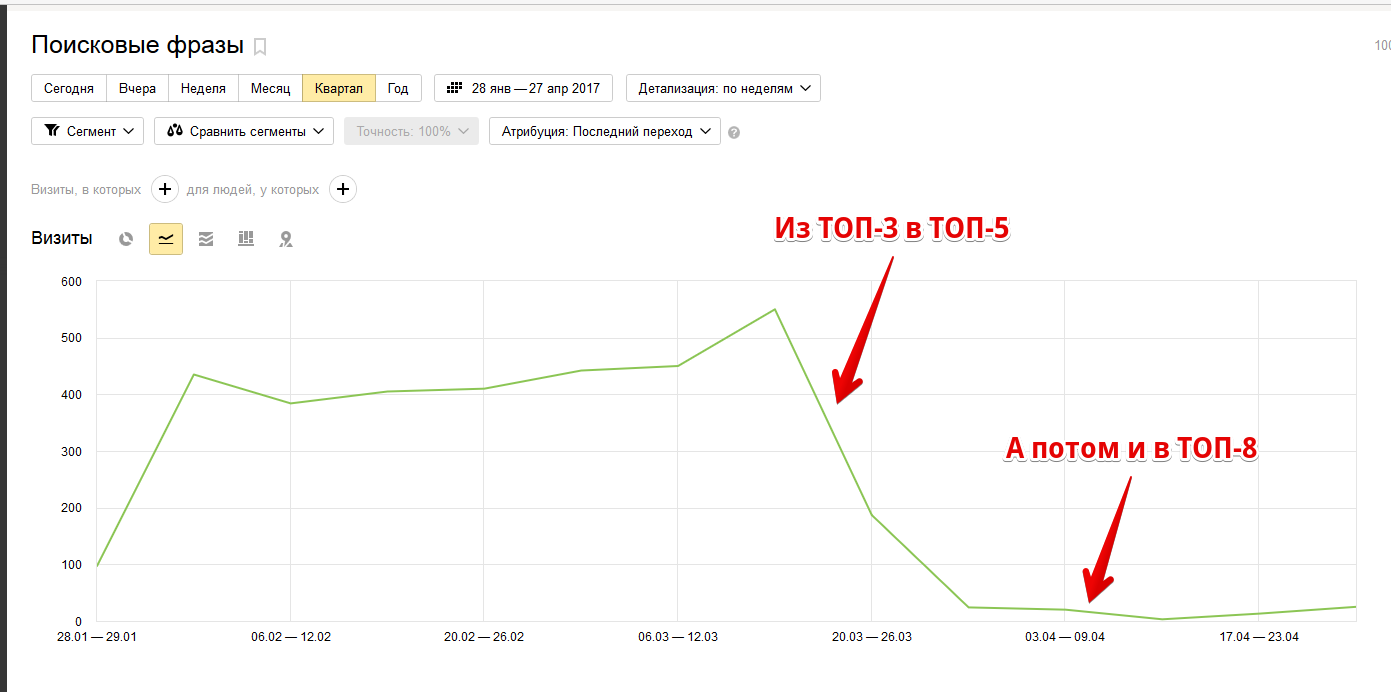
Падение существенно, наличие санкций несомненно. Так что никакой конкретной (или даже приблизительной) цифры назвать нельзя. Изменение позиций ведь зависит не только от размера штрафа но и от “силы” конкурентов.
Сравнительный анализ пострадавших и не пострадавших страниц
Наконец добрались до главного. Так как характер санкций – документный, то анализ сильно упрощается. Нет необходимости рассматривать все нюансы ранжирования по парам запрос-документ. Можно работать с самой страницей, ее наполнением.
Для каждой из 4297 страниц выборки рассчитывался ряд показателей. Затем они усреднялись сначала для конкретного сайта, а затем оценивались для выборки в целом.
Для каждого сайта и фактора применялась формула:
D = (B – N)/N*100%
где
- D – разница между значением показателя на “хороших” и “плохих” страницах, выраженная в процентах;
- B – средний показатель страниц сайта под Баден-Баденом;
- N – средний показатель нормальных страниц (где трафик стабилен или вырос).
Делить на N необходимо чтобы определить разницу в %, отследить, насколько сильно отличаются данные для разных факторов и сравнить их относительную значимость. Просто так сравнивать разницу между “нормой” и “плохими” страницами нельзя – ведь разные факторы измеряются в разных величинах.
Простая аналогия для тех, кто хочет понять методику интуитивно
Допустим, появилась новая болезнь и ученые ищут как с ней бороться. Одни люди поправляются за 1 день, другие – за месяц. Люди из этих двух групп очень разные – они отличаются ростом (метры!), весом (килограммы!), количеством гемоглобина в крови (хмм, не помню). Как можно понять, какое свойство организма дает защиту или наоборот приводит к тяжелой болезни?
Во-первых, надо изучить группы “здоровяков” и болевших долго, которые как можно больше схожи. Во-вторых, найти, какие характеристики организма у них разнятся сильнее всего. Отличие, конечно же, нужно считать не в метрах и килограммах, а переводить в проценты. Тогда можно сравнить любые показатели. Вот и вся суть формулы.
Возвращаемся к SEO.
Часть оценивавшихся факторов оперирует понятием “стоп-слов”. Для повышения достоверности они рассчитывались дважды – с коротким и расширенным списком. Значимых различий для этих вариантов выявлено не было. Результаты ниже приведены по измерениям с расширенным.
Пример расчета
UPDATE: в комменариях отмечают, что методика расчета показателей, которые приведены ниже, все-таки не до конца ясна. Давайте разберем на простом примере. Допустим на сайте есть 6 статей. Мы хотим понять, отличаются ли “хорошие” от “плохих” по объему текста.
Собираем вот такую статистику:
| Статья | Слов всего | Под фильтром |
|---|---|---|
| 1 | 1000 | Нет |
| 2 | 1200 | Нет |
| 3 | 1400 | Нет |
| 4 | 2000 | Да |
| 5 | 2200 | Да |
| 6 | 2400 | Да |
Теперь считаем среднее значение для страниц 1,2,3 (без фильтра) и для 4,5,6 (под фильтром). В первом случае это (1000 + 1200 + 1400)/3 = 1200. Во втором – (2000 + 2200 + 2400)/3 = 2200. Теперь, имея на руках средние значения, мы можем определить среднюю же разницу между теми, кто попал под фильтр и теми кто устоял.
Считаем:
2200 – 1200 = 1000.
Напоминаю, что мы считаем объем текста в словах. Но в дальнейшем нам нужно будет сравнить между собой самые разные показатели, которые измеряются в других единицах. Только так мы поймем, какие из них важны, а какие нет.
Поэтому теперь рассчитаем не просто разницу, а относительную разницу, т.е. переведем в проценты от нормы: 1000/1200*100% = 83%.
Теперь берем каждый сайт выборки и проделываем то же самое. Считаем среднее значение – вуаля, видим, насколько в целом по выборке “хорошие” страницы отличаются от “плохих” по объему текста. И так для каждого показателя.
Конечно, пример чисто для наглядности. На 6 объектах делать наблюдения нельзя, в реальности маленькие сайты я не рассматривал. Ну и как вы можете увидеть ниже, различия по объему текста совсем не в районе 80%.
Поведенческие факторы
Согласно заявлениям представителей Яндекса, в работе Баден-Бадена учитывается поведение пользователей. Поэтому в первую очередь я проверил базовые показатели активности посетителей на странице.
Результаты сравнения по формуле:
- процент отказов: -0,9%;
- средняя длительность посещения: 0,6%;
- глубина просмотра: 1,3%;
“Классическая” тошнота
Это всего лишь квадратный корень из количества вхождений самого частого слова. Результат несколько неожиданный: -2,7% (знак минус!). То есть тошнота на “нормальных” выше, чем на попавших под Баден-Баден. Мы вернемся к этому позже.
“Академическая” тошнота
Более сложный показатель, так как учитывает вхождения разных слов по отношению к объему текста. D = -3%. Точно так же – на “нормальных” текстах она оказалась выше.
Показатель вариативности текста
Рассчитывается как разница между единицей и отношением “уникальные леммы/уникальные словоформы”. D = -1,8%. Чуть больше на нормальных.
Показатель “водности” текста
Разница между единицей и отношением “количество слов после очистки стоп-слов/количество слов в исходном тексте”. Страница, вообще не содержащая стоп-слов будет иметь водность 0, содержащая только стоп-слова – 1.
D = 8,7%. Так-так! Водность на страницах, попавших под Баден-Баден, значительно выше.
Наличие “воды” в тексте оценивается многими метриками и это всегда негативный сигнал. Например, может страдать рейтинг по фактору Yandex Minimal Window.
Объем текста в словах
D = -1,8%. На нормальных чуть больше. Статистическая достоверность под сомнением, скорее нужно говорить об отсутствии разницы. Во всяком случае, дело не в размере как таковом (к комментариям под анонсом в блоге Яндекса были мнения, что фильтр накладывается на “портянки”).
Частота встречаемости биграмм
Для вычисления берется сумма числа вхождений трех самых частых биграмм – то есть сочетаний двух слов (например, типичный оборот в SEO-тексте “купить окна” сводится к биграмме “купить окно”). Сумма делится на количество слов в тексте, чтобы оценить относительную частоту.
D = 5,9%. Видим существенно больший показатель у “плохих” страниц.
Частота встречаемости триграмм
Расчет аналогичен, только берутся триграммы (“Купить пластиковые окна” => “купить пластиковый окно”).
D = 7,8%. Ого! Триграммами-то тексты под Баден-Баденом спамят еще сильнее!
Обсуждение результатов
Значение D по модулю (просто чтобы сравнить, как сильно отличаются разные показатели, независимо от того, больше или меньше они на страницах, где орудовал Баден-Баден):

Поведенческие факторы предсказуемо оказались в самом хвосте списка. Очевидно, паттерны поведения на разных страницах весьма сходны. Поэтому утверждение о том, что Баден-Баден учитывает поведение пользователей я рассматриваю в том смысле, что поведение учитывалось во время обучения алгоритма на выборках переоптимизированных и естественных текстов.
Максимально значимые отличия демонстрируют водность, частота триграмм и биграмм.
Любопытно, что “тошнота” текста на страницах, попавших под Баден-Баден, даже ниже чем на нормальных. Это наблюдение не нужно рассматривать как общее правило. Вспомните, что для анализа были отобраны только сайты с более-менее приличными текстами. Наверняка среди других проектов полно документов с обрушившимся трафиком и огромной тошнотой. Обилие вхождений Яндекс не приветствует уже давно (см. эксперимент).
Однако очевидно, что высокий показатель встречаемости слова – далеко не самый важный и универсальный признак спамного текста.
Вдумаемся в тот факт, что пострадавшие страницы одновременно имеют более низкую тошноту и более высокий рейтинг биграмм/триграмм. То и другое вычисляется по сходному принципу: встречаемость слова/количество слов и встречаемость биграммы/количество слов. Очевидно, что в нормальных текстах частота слова и частота биграммы, в которую оно входит, будет коррелировать. В спамных же этот порядок нарушен: частота отдельных слов оказывается не такой уж большой, зато они постоянно сбиваются в n-граммы.
Если совсем просто. Допустим, у нас есть хороший экспертный текст про пластиковые окна. Очень маловероятно, что в нем все слова из набора “пластиковый”, “окно”, “купить” будут постоянно встречаться вместе (попробуйте напрячь воображение). А вот если у копирайтера есть задача втиснуть десяток ключей в водянистый текст, при этом оставаясь в заданных рамках по “тошноте” – то иначе и получиться не может. Автор не сможет использовать слова из запроса где-то еще, кроме специально вставленных поисковых фраз.
Дополнительный показатель естественности
Чтобы проверить и заодно описать это наблюдение более строго, я рассчитал дополнительный показатель. Количество вхождений топовых триграмм в текст поделил на сумму вхождений слов из их состава. Получилась простая характеристика, описывающая, насколько часто популярные слова в тексте объединяются в триграммы.
Разница между страницами под Баден-Баденом и “нормальными” составила 9,4% (!). Это очень много (больше, чем любая другая метрика в этой статье).
Не тешу себя надеждой, что выделил именно те факторы, с помощью которых Яндекс выбирает, какие страницы считать переоптимизированными, а какие – нет. Наверняка алгоритм использует множество других метрик, куда более сложных. Однако более чем вероятно, что они тем или иным образом связаны с “водностью” и n-граммами. Различия слишком существенны, чтобы их игнорировать.
Важнейший результат – в том, что разница между очень похожими внешне “хорошими” и “плохими” текстами отлично улавливается сравнительно простыми показателями. Их вполне можно использовать для определения страниц, которые требуют особого внимания и первоочередных доработок.
В конце концов, наша задача проще, чем у Яндекса. Ему нужно было покарать спамные документы, задев как можно меньше добропорядочных. Нам же требуется просто расставить приоритеты; понять, на чем в первую очередь ловятся “плохие” страницы и исправить это. Особенно актуальна подобная проверка для сайтов, попавших под хостовый фильтр а также молодых проектов, где невозможно выделить проблемные страницы путем анализа трафика или позиций.
Коротко о главном
- Баден-Баден проявляет себя как фильтр, наложенный на документ (или хост), без привязки к конкретным запросам.
- Постраничный характер санкций позволяет провести сравнительный анализ документов с разной динамикой трафика после 22 марта и использовать результаты на практике.
- В ходе исследования не было выявлено прямое влияние поведенческих факторов. Различия относятся в первую очередь к текстовым метрикам.
- Для статейных сайтов относительно высокого качества выявлены следующие характеристики попавших под санкции страниц: высокая водность, высокая частота биграмм и триграмм, плохо коррелирующая с частотой входящих в них слов. Проще говоря, спамные тексты по мнению Яндекса содержат много стоп-слов, а также избыток устойчивых сочетаний из нескольких слов. При этом сама по себе частота устойчивых сочетаний может быть не слишком большой.
- Для интернет-магазинов и корпоративных сайтов наблюдаются схожие тенденции, однако в этом случае размер выборки не позволяет делать выводы с высокой степенью уверенности.
- “Тошнота”, как академическая, так и классическая, не является самостоятельным полезным сигналом.
- Для возврата трафика требуется повышение естественности текста. По всей видимости, Яндекс оценивает ее комплексно. Любые показатели следует воспринимать только как ориентиры, демонстрирующие лишь часть общей картины.
p.s. Не забываем о конкурсе! Кто объяснит, почему при наложении санкций снижается не только общий трафик, но и доля визитов по запросам, содержащим отсутствующие в тексте леммы?
p.p.s. Скоро напишу о том, как на практике применять полученные данные для работы с попавшими под раздачу сайтами. А также что делать тем, кто предусмотрительно хочет защитить свои проекты (напоминаю, что алгоритм, по словам Яндекса, еще не разгулялся в полную силу).
p.p.p.s. Лайки и репосты мотивируют делать новые исследования и делиться результатами 🙂
UPDATE: многих заинтересовало, чем проверять указанные в статье показатели. Выложил первую версию сервиса для этого (см. анонс).



Спасибо за информацию, очень интересно. Как раз сейчас перерабатываю упавший инфо-сайт, похоже на хостовый фильтр, так как просели почти все страницы, но в вебмастере сообщения нет. Подскажи, как и чем считал водность, биграммы и триграммы? Хочу посчитать для своего сайта.
Юрий, рад, что понравилось!
Параметры рассчитывал собственным скриптом. В ближайшее время функционал будет доступен на https://bez-bubna.com/
Отлично, буду очень ждать!
Как один из вариантов чистки текста от спамных ключей, придумал такой вариант. Выгружу метрику, скриптом найду точные вхождения в моих текстах и сравню с топ-10. Если в топе точных вхождений нет, а у меня есть — скорее всего, ключ неестественный и его упоминание будет лишним.
По сути вы реализуете собственный текстовый анализатор топа с одним параметром.
Методика может дать определенную информацию к размышлению, но здесь очень много нюансов. Даже к очень сложным текстовым анализаторам есть много вопросов – советую погулить статьи Людкевича на эту тему.
В трудах за Яндекс не забывайте про Гугл. У меня Гугл везде по всем всегда рулит под 70% трафика. Мне нужен Яндекс, но Гугл я ему не продам.
описанный вам метод используется в раках марафона Пузата для подсчёта требующегося количества употреблений ключей
Спасибо за исследование
>количество слов после очистки стоп-слов/количество слов в исходном тексте
А какие стоп слова использовались?, ведь от их выбора (фактически ваше субъективное мнение) и результат будет разным.
Вы правы, поэтому я использовал 2 разных списка (см. выше). Первый (базовый) просто загуглил. Второй, расширенный – результат долгого отбора, используется много где в сервисе поэтому делиться им не готов 🙂
А упрощённо принять все слова до 3-х букв за “стоп-слова” можно?
Вполне (именно до, не включая 3: кот, дом, дол… – вполне значащие слова)
Спасибо очень полезно, подскажите, а какой средний % водности хороших текстов получился и плохих? Или может дайте рекомендации до какого % следует придерживать водность текста на инфо статьях. И каким инструментом вы проверяли водность текста, а то на разных сервисах вижу по-разному считается он
Алексей, в следующем посте напишу подробно.
Да, про относительные значения – это хорошо. Но стоит знать и об абсолютных. Хотя понятно, что тематика и т.п. рулят 🙂
Да, очень интересно. Остается только узнать как проверять тексты на водность и какие параметры водности должны быть, чтобы не попасть под фильтр. И инструмент для расчета количества вхождений топовых триграмм в тексте, деленных на сумму вхождений слов из их состава плюс частоты би,-триграмм. Ждем инструментов!
Спасибо! Инструмент усиленно пилю 🙂
Кто объяснит, почему при наложении санкций снижается не только общий трафик, но и доля визитов по запросам, содержащим отсутствующие в тексте леммы?
Так ты ж вроде сам и объяснил, что фильтр накладывается постранично и там уже пофиг есть леммы в тексте или их нет. Страница такая то – стоп кран по всему что ее касается.
Видимо, я недостаточно ясно сформулировал. Суть вопроса в том, что трафик по таким запросам снижается СИЛЬНЕЕ, чем по остальным. Почему? 😉
1) А разве снижение трафика “СИЛЬНЕЕ” нельзя объяснить дополнительным СНИЖЕНИЕМ мест по запросам из выявленных частых би- и три-рамм? Вроде, ж это очевидно.
2) Об этом мой и вопрос )) я правильно понимаю, что Яндекс интересует НЕ просто пусть и малая частота НЕКОЕЙ би/триграммы, а то, что она ЕСТЬ ключ в его разумении, или ещё точнее выразится, по этой би-три-грамме на страницу идёт ТРАФик?
1. Юрий, в том и дело, что по n-граммам трафик падает слабее. Сильнее он падает по запросам, для которых не нашлось точных n-грамм.
2. Скорее нет, чем да.
Предположу, что при наложении фильтра обнуляется вся текстовая релевантность.
Артем, возможно и не вся, но согласен, что работает где-то в этом направлении.
Алексей, спасибо за Ваш анализ. Впечатлила тщательность подхода к проведению эксперимента. Попытаюсь это связать со своими данными по проектам.
>высокая водность, высокая частота биграмм и триграмм
А есть более точное определение слову высокая? Какие значения в цифрах считаются нормальными, а какие уже уходят под фильтр?
А работа конечно большая, спасибо за труды.
Вадим, не думаю, что есть единый порог. Разве что ориентиры (но скорее всего увязанные с другими факторами). В любом случае, это надо исследовать дополнительно.
“1. Юрий, в том и дело, что по n-граммам трафик падает слабее. Сильнее он падает по запросам, для которых не нашлось точных n-грамм”
Ну так всё понятно! Они включают Б-Баден, но “мозги” не успевают и они вынуждены в этот момент отключать Палех и прочий “Иск интеллект”, который с их же слов призван понять (как и у Гугла) что текст о “собаках”, хотя “собаки” ни разу не упоминались!
Теплее 🙂
слова, которые задают тематику, синонимы по словам (под которые оптимизированы страницы)
И?
Вопрос звучит:
Кто объяснит, почему при наложении санкций снижается не только общий трафик, но и доля визитов по запросам, содержащим отсутствующие в тексте леммы?
Отсутствующие в тексте леммы (по которым идет синжение) – это скорее всего синонимы, тематикозадающие слова. Их в тексте нет, но Яндекс понимает, что по этим запросам можно ранжировать этот документ.
По таким запросам (которые содержат синонимы, тематикозадающие слова) сильнее падает, так как их нет в тексте в точном вхождении. И если это так, значит что-то в момент наложения санкций отключается (часть алгоритма, где как раз про синонимы и тематикозадающие слова). Как-то так.
Тепло, но не совсем.
Что такое хостовый фильтр? Фильтр на весь сайт?
Да
Алексей, спасибо за ваше исследование.
Уточните, пожалуйста, частота триграмм и биграмм анализировалась по такой методике или нет:
1) лематизируется текст своей постарадавшей статьи и нескольких сайтов в топе по главному запросу.
2) Считается рейтинг самых популярных биграмм (кол-во биграммы в тексте деленное на количество слов в тексте), например топ 5.
3) Считается рейтинг самых популярных триграмм (кол-во триграммы в тексте деленное на количество слов в тексте), например топ 5.
4) Каким-то образом это все между собой сравнивается. Каким?
Евгений, ТОП не использовался вообще (как было показано в статье, санкции документ-зависимые, анализировать запросы нет смысла). Просто лемматизировал текст и выделял n-граммы. Ну а дальше все как в примере расчета.
А что с чем сравнивалось тогда? Все упавшие статьи со всеми не упавшими?
И как шло само сравнение…
Допустим, статья постадавшая от бадена:
биграмма 1 – 2.3%
биграмма 2 – 1.5%
…
биграмма 10 – 1.9%
Статья не пострадавшая от бадена:
биграмма 1 – 1.3%
биграмма 2 – 1.7%
…
биграмма 10 – 1.3%
Что с этим делать, чтобы получить статистически значимые данные?
См. пример в середине статьи, там все расписано.
> Разница между страницами под Баден-Баденом и «нормальными» составила 9,4% (!). Это очень много (больше, чем любая другая метрика в этой статье).
Провели свой собственный расчет “показателя естественности” по вашему алгоритму на статьях на одном из наших сайтов.
Цифры совпали с вашими.
Разница в “показатели естественности” между упавшими и не упавшими статьями как раз в среднем около 10% и получилась.
То есть, ваша гипотеза у нас подтверждается 🙂
Спасибо за дополнение!
Ну т.е. получается что нужно работать над уменьшением спамности n-грамм, но может упасть трафик с гугл. Или же увеличить кол-во вхождений составляющих слов? Тогда все в плюсе)
Ну второй вариант для совсем отважных 🙂
Для анализа “водности” достаточно стопслов, по которым проверяет text.ru/seo?
Не изучал толком их списки.
Проверял по 2 собственным (разумеется, наиболее полный будет в составе инструмента по анализу текстов в https://bez-bubna.com/)
В тексте про красную волчанку биграмма [красный волчанка], вероятно, будет употребляться часто. В то время как по отдельности слова, в неё входящие – редко.
Я думаю, надо сопостпвлять частоту встречания биграмм/триграмм в тексте с частотой встречания в коллекции документов (эталонная, тематическая или эталонная тематмческая – не знаю, на что яндекс ориентируется).
Скорее всего, частое употребление биграммы [красный волчанка] – это нормально. Но употребление триграмм [симтом красный волчанка] и [лечение красный волчанка] – уже неестесственно.
Михаил, отличное замечание.
Поэтому и выделил показатель естественности именно по триграммам – естественных сочетаний из 3 слов куда меньше.
Тем не менее, совсем сбрасывать со счета биграммы тоже нельзя, так как различия по их рейтингу на выборке тоже оказались довольно высокими.
А есть какие то цифры по абсолютным пороговым значениям, например, процент бинрамм от объема текста или процент бинрамм от количества слов их составляющих в тексте?
На разных сайтах отличались, не обращал особого внимания на этот параметр. Думаю, в зависимости от тематики “порог спамности” сильно меняется, так что особого смысла его выделять нет.
Какой-то переизбыток информации … В сухом остатке: Баден-Баден — это наш ДРУГ, позволяющий более точно направить трафик по би/триграммам (т.е. тем же ключам), правда снижая трафик по НЕключам, для которых мы “заточим” би/триграммами мало посещаемые страницы нашего сайта …
Нужен рабочий алгоритм. А то все размыто. И трафик вниз. Уже 20стр разных опытов. А толку ….ноль
Очень круто, когда будет функционал в сервис ?
Постараюсь на следующей неделе, хотя могу и запоздать чуток из-за конфы: http://alexeytrudov.com/web-marketing/seo/19-maya-vyistupayu-na-sempro.html
Крутая комфа будет. Я так понимаю кто туда не попадет. Все будет под семи замками? Будет ли запись ???
Не в курсе)
Свою презу выложу
Ждем сервиса с нетерпением. Одна просьба, чтобы можно было не только URL, как у вас в bez-bubna.com подгружать, но и чистый текст проверять на воду, спамность, би,-триграммы и т.д.
Хорошо, сделаю и такой режим
Алексей, приветствую!
Есть новости по этому вопросу?
С нетерпением жду, чтобы потратить деньги в сервисе ! 🙂
Потихоньку дело двигается, но новостей нет)
С SEMPRO я на неделю выпал из нормальной работы. Но скоро надеюсь будет чем порадовать.
Да, бета-версия уже давно есть (если вдруг пропустил): http://alexeytrudov.com/web-marketing/service/paketnyiy-analiz-teksta-i-otsenka-izmeneniya-trafika-stranits.html
Не совсем понял как считать.
Допустим в исходном тексте есть триграмма “купить розового слона”, которая встречается 3 раза.
Слова по отдельности встречаются:
“купить” – 5 раз,
“розовый” – 7 раз,
“слон” – 11 раз.
Получается что нам надо:
3 “купить розового слона” / (5 “купить” + 7 “розовый” + 11 “слон”) = 0,1304 * 100% = 13,04 %
Правильно я понимаю? Или нужно суммировать все триграммы и потом разделить на сумму входящих в них слов?
Виктор, второй вариант. Это приводит к дополнительному увеличению индекса, если слово входит в несколько популярных триграмм. Только не все триграммы, а 3 самые частотные.
Алексей, а как Вы поступаете, если топ триграмм выглядит как 5,4,3,3,2 т.е. на третьем месте сразу несколько триграмм?
отбрасываете те триграммы, которые имеют частотность 3, берете все триграммы или берете только одну?
Дмитрий, хороший вопрос. Я брал только одну. Для большей точности, разумеется, нужно прорабатывать этот момент. Я не заострял на нем внимание, так как это чисто исследовательская метрика, которая проверялась вместе с множеством других. Здесь было важно выделить общие тенденции. Вполне может быть, что отличия лучше ловятся, например, по ТОП-10 триграмм. Или показателю всех триграмм, которые встречаются больше одного раза. Продолжаю изучать эту тему чтобы для практики выделить более показательные ориентиры.
Вообще, сам факт, что даже на таких грубых параметрах ловятся достоверные различия говорит о многом.
Спасибо большое за материал, очень полезен.
Но подскажите пожалуйста чем, каким инструментом можно проверить “высокую водность” или “высокую частоту биграмм и триграмм” например по пачке урлов?
Т.е. попал под Баден, тексты не везде плохие, страниц сотни, хочу сузить область поиска, например по сотне урлов проверить, какие из этой сотни плохие или хотя бы “подозрительные”
Заранее благодарю за развернутый ответ
Алексей, буквально вчера выложил инструмент для этого (пока сыро, но скоро доработаю).
http://alexeytrudov.com/web-marketing/service/paketnyiy-analiz-teksta-i-otsenka-izmeneniya-trafika-stranits.html
Как определили, на какие страницы наложен алгоритм Баден-Баден ?
Все есть в посте. Трафик на странице просел в районе 22 марта – считаем что Баден-Баден. Это не всегда так, могут быть и другие причины, но на большой выборке влияние других факторов нивелируется.
Здравствуйте!
Спасибо за весьма познавательные материалы! Но подскажите, имеет ли значение url. Допустим, тайтл статьи – фраза из 4-5 слов, которая полностью совпадает с H1 и url. Хлебных крошек нет. Это плохо? Т.е. подсчитывая кол-во вхождений словосочетания, считать ли вхождения в url и тайтл?
Для исследования я пробовал и включать тайтл и не включать. Конечные соотношения от этого поменялись мало. По url не считал.
Но надо понимать, что я работал с выборкой “приличных” страниц, где тайтлы содержали не так много n-грамм. Получить по шапке за спамный тайтл можно 🙂
Кто объяснит, почему при наложении санкций снижается не только общий трафик, но и доля визитов по запросам, содержащим отсутствующие в тексте леммы?
Леха, интригант))) Может дело в технологии “Спектр” ?
🙂
Нет)
))) фильтр документнозависимый, я правильно понял, что с Яндекса на этот документ траф прекращается по всем запросам? При чем тут леммы тогда?)))
При том)
Помогите советом, если можете. Так совпало, что на сайт напали фильтры (баден, а 8 февраля гугл) после того как комментарии к статьям были добавлены в табы (закладки). Комментариев много, десятки, сотни. И получается что они загружаются с display:none. По идее могли за такое наказать?
И комментарии с баденом вообще, может отправить в ссылку за возможный переспам в комментариях?
По идее – да, но вряд ли. Скорее за переспам в комментариях – с этим очень просто загреметь. И на практике не раз видел, и в эксперименте тоже весьма явственно было.
что посоветуете? разделить комменты на страницы пагинации, скажем штук 20 на страницу, таким образом совсем отсечь остальные комментарии от видимости ПС
Лучше всего убрать спамные, оставить приличные. Но и у вас вполне рабочая идея (и наверняка менее затратная в плане реализации)
Первый раз за последний год наверное я прочитал что-то годное по SEO.. Добавил в закладки.
Ого 🙂
Спасибо!
А можно уточнить, на bez-bubna.com пакетный анализ текстов не работает? Или это у меня проблемы просто.
Проверил, вроде все штатно. Что именно не работает? Лучше на почту support@bez-bubna.com, разберемся
А вот про это нельзя сказать так, не замечали, не смотрели такого?
“Для статейных сайтов относительно высокого качества выявлены следующие характеристики попавших под санкции страниц: высокая водность, высокая частота биграмм и триграмм, плохо коррелирующая с частотой входящих в них слов. ”
Нужно чтобы кол-во биграмм и триграмм было меньше чем кол-во униграмм входящий в них слов?
Не думаю, что тут есть жесткое правило. Некоторые биграммы устойчивы и в естественном языке. Например, на вебинаре был хороший пример – “Болезнь Альтцгеймера”. Вообще, обычно довольно легко выделить ненатуральные биграммы, особенно если знать, что их стоит поискать (для чего и нужен инструмент).
инструментов пользовался, он показывает процентное соотношение. Вы тут пишете про натуральность, есть инструмент который проверяет неестественные биграммы, триграммы?
Нет, потому что это очень сложно сделать. Высокое соотношение и одновременно высокая тошнота n-грамм – это повод заподозрить такую неестественность.
Кстати сейчас пришло в голову гипотеза? считатется ли спамом повторение в title названия своего сайта. Обычно так делают в конце ставя.
Например: ***текст тайтла*** – demipe.ru У вас нет каких исследований и данных на этот счет?
С этим баденом теперь не знаешь где может вылезти переспам, хотя до этого было нормой.
99,999% что за это санкций не будет. Если только само название не спамное)
а если дискрипшен повторяется на всех страницах за исключением замены названия услуги?
напр: Организация и проведение активного тимбилдинга на природе в Москве и области. Только у нас проведение на любой бюджет и в любое время суток. Пишите – info@demipe.ru
Организация и проведение творческого тимбилдинга на природе в Москве и области. Только у нас проведение на любой бюджет и в любое время суток. Пишите – info@demipe.ru
Меняется только названия услуги.
Недавно где прочитал статью про баден, писали, что повторяющиеся призывы к действию на всех страницах то же под Баден. Напр пишут же, если вы хотите заказать *такую то услугу* то звоните по номеру телефона ****
То же меняется только название услуги.
Могут быть какие-то санкции (например, вылет страницы из индекса как “недостаточно качественной”), но не только за дескрипшен, а по совокупности (так ли различаются активный и творческий, что для них нужны разные url?). Баден-Бадена из-за такого не встречал. Вообще, не думаю, что это особо важный фактор, огромное количество сайтов так делает и особых проблем там не наблюдается.
Алексей, добрый день! пользуюсь вашим сервисом, и кое-что непонятно. К сожалению, я пенсионерка, и голова у меня не такая светлая, как у вас, молодых. Так что, если вопросы будут глупыми, не смейтесь.
Анализ статьи показал, что вариативность – 0.299, водность – 0.303, тошнота биграмм – 2,156 , тошнота триграмм – 1,232, Индекс биграммы/униграммы 37,5 Индекс триграммы/униграммы 15,789
У меня есть табличка. на которую я ориентируюсь:
• Водность 0,31 и более.
• Вариативность 0,23 и менее.
• Тошноту биграмм 3,6 и более
• Тошноту триграмм 1,8 и более.
• Индекс биграммы/униграммы 32 и более.
• Индекс триграммы/униграммы 17 и более.
получается, что у меня превышен индекс биграммы-униграммы. А все остальные показатели в норме. Как это исправить? Убирать водность или добавить униграммы?
И еще вопрос: показатели при анализе и вот та табличка, на которую я ориентируюсь, могут сильно расходиться? или статью пытаться подгонять ближе к этим показателям в табличке.
Сайт поначалу от Бадена не сильно пострадал, хотя проседание было тысячи на 3. А сейчас не падает, но и роста нет, хотя статьи пишу регулярно.
Пожалуйста, ответьте.
Галина, добрый день!
Распространенный вопрос, добавил уточнение в конец статьи с порогами: http://alexeytrudov.com/web-marketing/seo/baden-baden-gde-porogi.html
Скорее всего, можно не исправлять, показатели вполне нормальные (если тем не менее со страницей неладно – значит, нужно перерабатывать более глубоко, добавлять ценный контент).
Безусловно могут! Подгонять не надо! Каждый текст уникален. Это чисто отправная точка для новых статей. Лучше ориентироваться на средние/медианные значения по успешным страницам, которых Баден-Баден не накрыл. А еще лучше – просто стараться сделать хороший текст. Показатели только дают сигнал, где может быть проблема. Но далеко не всегда к сигналу нужно прислушиваться. Если смотрели вебинар – там был пример, где спамные показатели имела страница с совершенно “белого” сайта.
Еще раз, самое главное: параметры из сервиса только чуть-чуть подсказывают, где может быть проблема. Если попытаться впихнуть в них текст – ничего хорошего не выйдет.
Тут сложно что-то сказать, причин может быть много. Я бы для начала посмотрел, как меняется трафик по конкретным страницам. Какие набирают посетителей, какие теряют, удалось ли вывести из под фильтра старые и так далее.
Вопрос по Баден-Бадену: у меня до апреля по запросу ранжировалась страница, которая была оптимизирована под этот запрос, а потом Яндекс стал ранжировать другую страницу, главную (там тоже содержится ключевое слово), ну и позиции просели в течении 3-4 месяцев. Возможно такое, что документный фильтр был наложен на эту страницу, и поэтому стала ранжироваться главная по этому запросу? Часто такое видели? Или что это может быть если не документный фильтр?
P.S.: У меня страница под запрос состоит в основном из списков (списки производимых работ, используемого оборудования и т.д.), в таком формате крайне трудно добиться вариативности, как быть в таком случае?
Смена релевантной – это частая проблема. Не обязательно документный фильтр, может быть и запросный (и не фильтр вообще).
Для страниц-списков не стоит заморачиваться с вариативностью. Все метрики исследовались для статейных проектов.
Спасибо что ответили.
Два вопроса:
1. У меня траф также сильно упал, в 2,5 раза, а Яндекс в диагностике пишет – “На сайте не обнаружено нарушений и угроз, которые могут отображаться в этом разделе”. Так как это понимать?
2. Если у многих Сеошников трафик упал, значит где-то он прибавился. А прибавился ли он на самом деле или что-то другое происходит?
1. Так и понимать – Баден-Баден встроен в алгоритм, сигнал в Вебмастере бывает только когда накладываются хостовые санкции. Вам могло задеть 20 самых важных страниц из 500 например – вот и результат.
2. Чтобы ответить, надо обладать данными о всех сайтах Рунета. Но рост скорее всего не так заметен. Ведь если вы вылетели из ТОП-3 в ТОП-50, то сразу это почувствуете. А подвижка из ТОП-3 в ТОП-2 может и несильно на трафике отразиться.
Алексей, как считаете через 301 редирект в рамках одного сайта передается баден-баден?
У меня есть ощущение что передается, т.к. после 301 редиректа есть существенных рост позиций по всей группе ключей, а через несколько апдейтов, такое же существенное падение позиций для всей группы ключей.
При том что страницы были переписаны и проверены на сервисе (bez-bubna.com) еще на старом урле и только потом перенесены 301 редиректом.
Александр, думаю дело не в передаче, в том, что страница остается переоптимизированной с точки зрения поиска. Проверка это полдела, возможно Яндекс считает что на этих страницах вообще текст не нужен (например). Или текст формально улучшили, вписались в параметры но он остался “водным”.
Почему наблюдается такая картина – думаю, дело в том, что оценка текста для включения/выключения Баден-Бадена требует серьезных вычислительных ресурсов. Это не подсчитать вхождения, это явно комплексный алгоритм (скорее всего с учетом всего корпуса текстов на сайтах-конкурентах). То есть оценка происходит позже индексации. Появился новый url – для него посчиталась часть факторов, по ним нормально отранжировался. Потом не спеша рассчитали все целиком – и наложили санкции.
Алексей, спасибо за анализ!
На одном из инфосайтов улетела под ББ статья, дававшая раньше много трафика. Я проанализировал её по нескольким текстовым анализаторам, включая без-бубна, а также взял страницы из текущего топ-3.
Удивительным оказалось значение «тошнота триграмм». Для топ-1 она равняется 263, для топ-3 — 203, для моего сайта (на 46 месте в сёрпе) — 34. Хотя по идее должно быть наоборот. Как прокомментируете такие значения? Может ли это быть просто случайностью? Или эти два конкурента тоже скоро под ББ улетят, просто до них ещё не добрался алгоритм?
Максим, предположу, что анализировали текст с какими-то дополнительными элементами (ссылки в меню, например). То есть были учтены “технические” повторения n-грамм, которые не свидетельствуют о плохом тексте. Еще может быть так, что для вашей тематики это адекватно (например, в юриспруденции часто не обойтись без повторов одной и той же формулировки). В целом – лучше смотреть все показатели в комплексе (и даже тогда нет гарантии, что мы будем отделять “хорошие” от “плохих”, ситуация сложнее).
Это вы зря. Не надо слушать яндекса. Ох как он банит на вхождения в другие элементы не входящие в основной текст. И так же не ранжирует без них, если у конкурентов они есть. Яндекс любит лапшу на уши развешивать. Говорю из своих проектов.
Согласен, анализируется вся страница и легко может банить, но все равно сквозные элементы дают меньший вклад.
Кажется, разобрался в чём причина. После небольших правок текста я отправил страницу на повторную проверку. В основном исправлял явные грамматические и пунктуационные ошибки, ключи не трогал. В результате получил в новом анализе величину «тошноты триграмм», равную 341.
Получается, что в первый раз где-то потерялась последняя цифра. На всякий случай открыл ещё раз первый отчёт — там 34, не 340 и не 341.
При значении 341 всё встаёт на свои места, переспам действительно есть и позиции заслуженные)
Бывает и так да)
Это произошло 10 октября 2017г. получил сообщение – Малополезный контент, спам, избыток рекламы. Позиции сайта в результатах поиска понижены.
Пять месяцев я ни чего не размещал и ни чего не делал с сайтом, а вот одна и страниц начала хорошо расти и после этого ушла в полный – ноль. Тиц 10 остался прежним.
Что это было?
Даже сам Платон Щукин соизволил ответить что после повторной проверки всё остается в силе. Было два рекламных кода внутри статей при трафе до 20 в день при 40 страницах. Может из-за рекламы на сайте?
Может быть много причин, начиная от взлома с заливкой дорвея и заканчивая недостаточным, с точки зрения Яндекса, качеством контента. Надо сайт смотреть, как минимум экспресс-аудит сделать. Ну и с Платоном дальше работать, чтобы привели примеры страниц, нарушающих правила.
Алексей, можно вопрос? А почему вы использовали этот критерий для отбора сайтов:
“Где трафик с Google также имел выраженную тенденцию к снижению.”
Мы же вроде обсуждаем алгоритм Яндекса. Какая взаимосвязь?
Все просто. Если трафик снижается только в одной поисковой системе – это позволяет с большей уверенностью сделать вывод, что проблемы вызваны именно новым алгоритмом. А если падает и там и там – тут непонятно, может просто поисковый спрос уменьшается. Или на самом сайте какая-то проблема, которую сейчас не отследить. В общем, для чистоты выборки такие сайты лучше не смотреть.
Слово “тошнота” в статье встречается 16 раз.
Что вы скажите об этой цитате.
“Яндекс не оперирует понятием “тошнота”, пожалуйста, не привязывайте показатели ранжирования к этому странному показателю. Кроме того, не нужно думать, что алгоритмы в 2017 году реально единственное, что умеют – это считать ключи.
Elena Pershina, Яндекс”
Цитата абсолютно правильная. В выводах у меня, кстати, написано о том же. Но, как я уже говорил, в сочетании с другими факторами может быть полезным показателем. В текстовом анализе так всегда – нет одного универсального показателя.
Ну и надо понимать, что тошнотой они не оперируют, а вот показателями типа BM25, которые вполне себе коррелируют с ней – да.
Алексей, спасибо вам за проделанный анализ!
Скажите, пожалуйста, на сегодняшний день есть более-менее работающий алгоритм выхода из-под документного (не хостового) фильтра ББ?
На группе сайтов трафик упал в 2,5 раза, при том, что никакой жесткой оптимизации под ключи не было. Есть ли смысл пытаться менять контент, подстраиваться под те показатели, которые вы рекомендуете? Если да, то направьте, где у вас можно об этом почитать, поэалуйста.
Или же чаще всего проще потратить эти же силы на новый проект, оатсвив на старом все как есть и угасающий трафик?
Сергей, рад, что понравилось.
Алгоритм простой – улучшаем контент, но не подстраиваясь под показатели, а просто используя их как ориентиры (здесь удаляем вхождения, а здесь – высушиваем, добавляем конкретики). Успешные кейсы выхода есть, их довольно много.
Посмотрите мой вебинар и еще вот эту памятку.
До конца года надеюсь завершить анализ еще одной группы факторов, менее явной, чем вхождения и водность.
Алексей подскажите статью у вас на блоге не могу найти по этой проблеме и фильтр какой? Где видел про, сейчас не могу найти. Суть: сайт-каталог имеет 3000 страниц. Большинство страниц это карточки образцов рукоделия. (как в интернет магазине, только инфо сайт). Трафик в основном идет на категории т.к по ним ищут ключи. Что-то думаю, что могли санкции наложить за это. Вы вроде писали, что позиции могут не просесть у сайта из-за этого (когда страниц с трафиком меньше чем страниц без трафика), а просто общий трафик упадет. Либо я не правильно понял, вот хотел еще раз перечитать и вникнуть.
Юрий, вообще-то для каталогов это нормальная ситуация, когда трафик собирают в первую очередь категории. Но бывает и так, что карточки выделяются неоправданно и действительно вредят позициям других страниц. Это ярко проявляется в обновлениях алгоритмов Google в 2017. Подробно – здесь: http://alexeytrudov.com/google-fred/
Сам не изучал, но коллеги говорят, что аналогичное есть и в Яндексе.
Алексей, а что Вы думаете про переспам у гугла? Не по тому же он принципу определяется?
Определяется несколько иначе. Другой вопрос, что действительно переоптимизированные тексты будут выявляться по любым критериям. И страницы, которые карает Яндекс – в зоне риска для Google. Вот пост на близкую тему: https://alexeytrudov.com/web-marketing/seo/bolshoy-obzor-obnovleniya-algoritma-google-sentyabr-2017.html
Ооо, спасибо, то что нужно. Странно, помню начало статьи (видимо уже читал), саму статью не помню, странно, что отвлекло меня от прочтения столь актуальной для меня информации – прямо законы “Мерфи” в действии.
Я про анализировал проекты, которые у меня упрямо не идут в гугл (а таких малый процент в отличии от яндекс) и пришел к выводу, что их копирайтеры как раз очень переспамливают текст похожими триграммами (к биграммам гугл вроде бы более лоялен).
Тестирую сейчас Ваш сервис (без-бубна), очень все нравится, но не могу как раз найти есть ли там анализ на переспам, конкретной страницы? Нашел что-то в проработке страниц (но у меня там к сожалению, всего 30% от всех страниц сайта)
Не за что.
Да, после написания статьи видел ряд похожих примеров еще.
Есть форма для анализа отдельного текста, инструмент называется “Расширенный анализ текста”
Добрый день. Стаья хорошая – пытаюсь сопоставить с другой статьей.
Читал статью на ПиксельТулз.
Там они разделяют на Запросозависимый фильтр
Документ проседает только по основному запросу и при этом продолжает работать по более НЧ.
К примеру Запос типа “Мультик про Виннипуха” у меня переместился на 4 страницу
При этом – если написать в поиске Яндекса – “Мультик про Виннипуха с фото”
Топ страница появляется в топ 3 как и раньше .
При этом работает такой вариант как абра-кадабра “Мультик про Виннипуха омовам” – и я сново в ТОпе 1-3
Это давний спор 🙂
Вариантов объяснения тут примерно миллион.
Не исключено, что ваша страница не под (не только под) Баден-Баденом, например.