
Проверка индексации – рутинная задача SEO-специалиста, во множестве вопросов оптимизации без этого никуда.
А вы уверены, что выполняете ее правильно?
Если бегло прогуглить вопрос из заголовка, нам выпадет куча инструкций для начинающих. В массе своей они сводятся к двум советам:
- Используйте оператор site: (полный запрос для отображения всех страниц ресурса выглядит так – site:domain.ru);
- Отправляйтесь на сервис (ссылка на милый автору статьи ресурс), там есть красивая кнопка “узнать”, нажимаете ее и радуетесь.
По сути, это один и тот же совет, так как значительная часть сервисов аналогичным образом дергает выдачу Google и смотрит цифры в строчке “Результатов:”.
Это легко проверить.
Возьмем первый попавшийся заграничный сервис (замечу, что “первый попавшийся” в случае поиска в Google означает “достаточно популярный”):
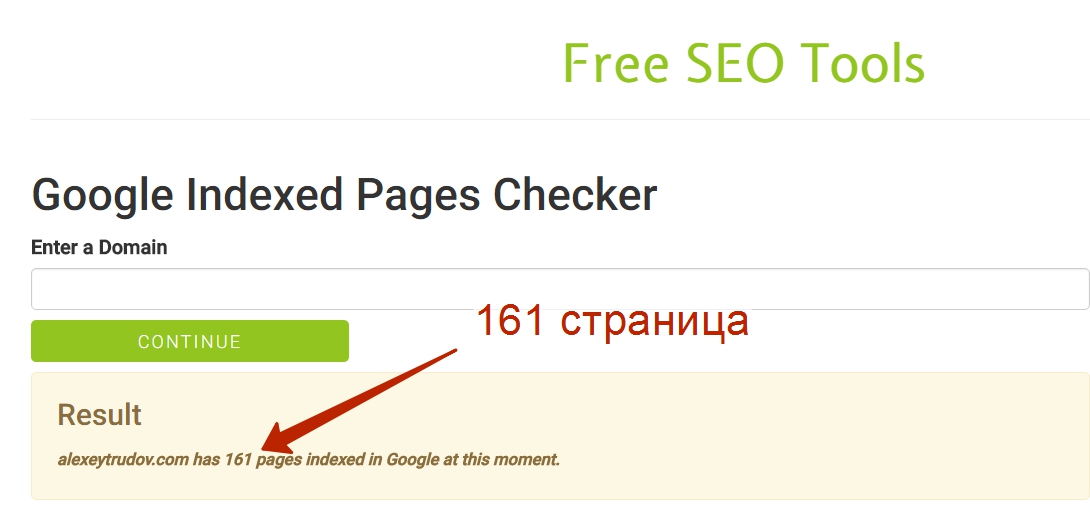
Глянем выдачу:
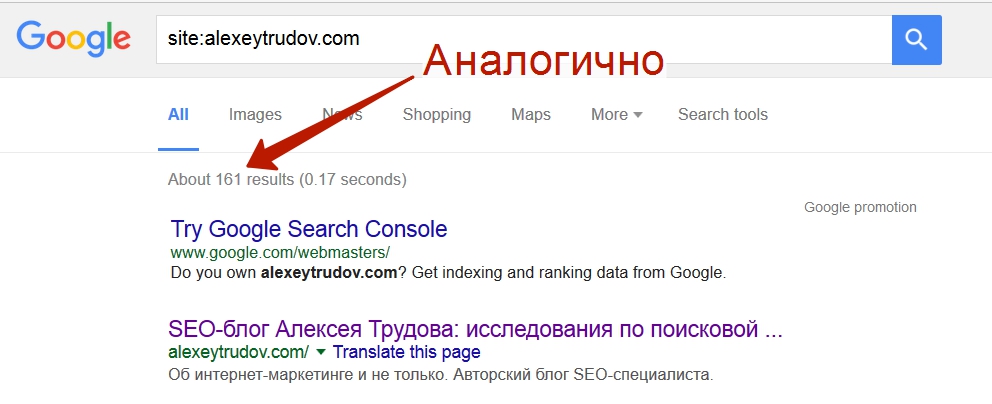
Вроде бы все верно, да? Нет, не совсем.
Зачем придумывать что-то еще? Разве оператор site: работает неправильно?
С оператором все более-менее в порядке. Проблема в том, что Google не зря пишет “Результатов: примерно”. Реальное количество страниц в выдаче может сильно отличаться от указанного под поисковой строкой.
В этом легко убедиться, если прогуляться вглубь выдачи: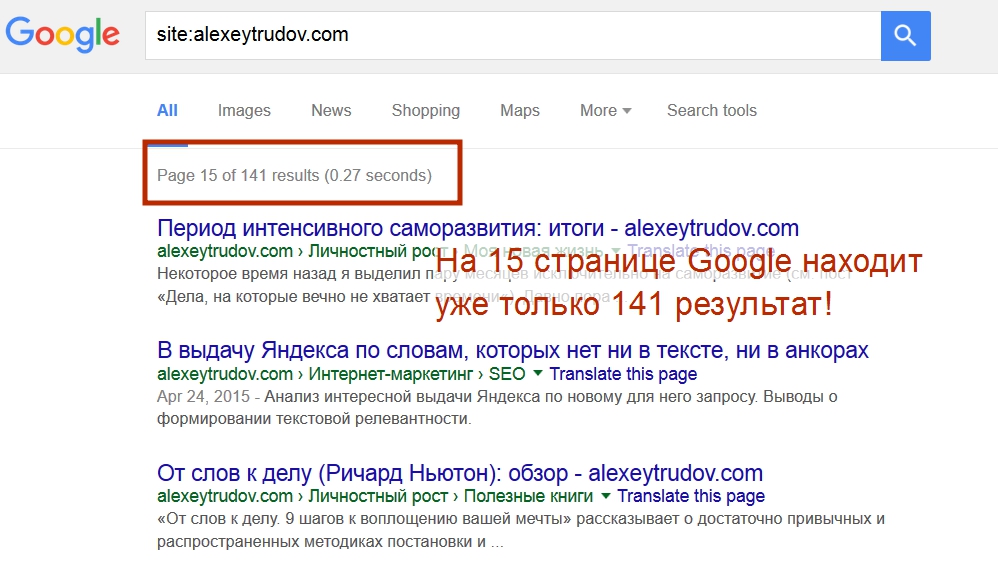
Кстати, здесь уже речь идет о точном числе результатов (из строчки пропало слово “about”). В данном случае результат похож на правду (говорю на основе хорошего знания своего сайта).
Ну и что? Разница не так уж велика. Подумаешь, 20 страниц
Разница в 20 страниц – это только один пример. На более крупных сайтах различие может быть разительным. Вот пара скриншотов выдачи, которую я получил, делая аудит для одного из своих клиентов:
 А теперь пару раз нажмем на пагинацию. Фокус-покус:
А теперь пару раз нажмем на пагинацию. Фокус-покус:
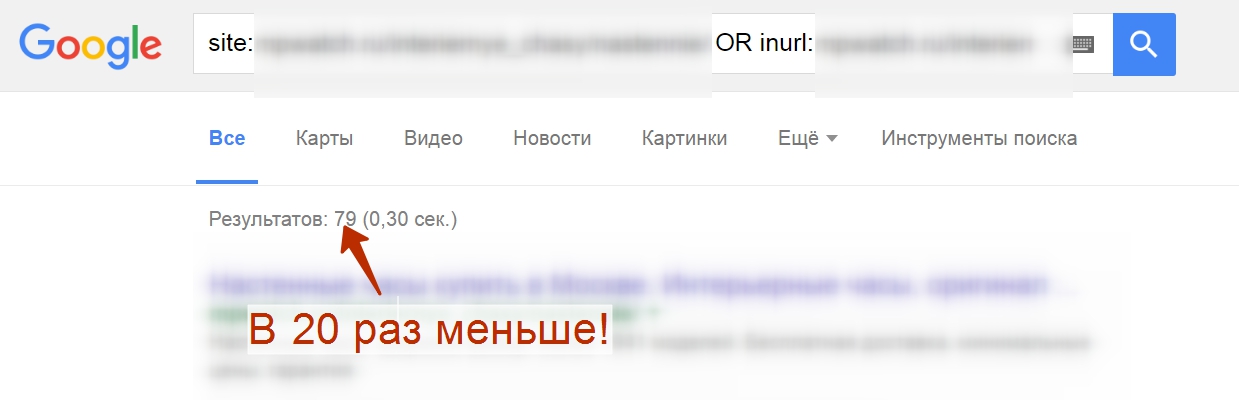
Почему так происходит?
Это несоответствие известно довольно давно. Вот, например, ответ бывшего инженера Google на Quora, данный еще в 2011 году:
That count is an estimate. What makes it hard to produce an accurate number is that your query is run in parallel across a number of machines. The final result count is extrapolated from the results returned and incorporates a number of factors. Google doesn’t want to actually return all of the results for a query, just the first few that really matter and then it estimates how many total results there are for the query. It’ll go fetch the others later if you page through extra pages (which very few people do).
Смысл в том, что Google ради скорости и экономии машинных ресурсов не стремится найти все ответы на вопрос. Для подавляющего большинства пользователей хватает первой десятки результатов. Искать и подсчитывать остальные имеет смысл только тогда, когда пользователь явно этого захотел, перейдя вглубь выдачи.
Ну и конечно, Гугл в последнюю очередь думает об удобстве оптимизаторов. Кстати, а откуда известно, что число на конечной странице выдачи действительно точное? Джентльмены верят на слово? Ну так то джентльмены, а сеошникам это не к лицу.
Да, в примере с моим блогом это работает. Но одного кейса недостаточно, чтобы выявить закономерность.
Вот результаты проверки еще одного сайта. Сначала я замерил количество страниц в индексе раздела, а потом – нескольких его подразделов. Результаты в табличке:

Вот так. “Точное” число в конце выдачи вовсе не отражает реальное количество проиндексированных страниц. Подразделов еще много, по порядку цифр к истине ближе оценочное значение.
Думаю, к этому моменту мне удалось навести основательный сумбур в голове читателя. Кому верить? На что ориентироваться, если и первая и вторая оценки неверные? Попробуем разобраться.
Как получить точное количество страниц в индексе?
Общий принцип понять несложно: мы должны скормить поисковику такой запрос, который он не сможет выполнить “на лету” и для которого “не захочет” обрезать выдачу (т.е. она не должна оказаться слишком длинной и однообразной).
Например это такой запрос, для которого придется сначала найти все результаты, а потом пропустить их через уточняющий фильтр.
Именно поэтому я для демонстрации на скриншотах выше пытался присоединить к оператору site: его “синоним” для данной ситуации – inurl. Как видите, это не сработало. Гугл умеет оптимизировать подобные конструкции и снова выдает приблизительный результат, который меняется при переходе к концу выдачи. Что делать?
Простого универсального решения нет (по крайней мере я его не нашел).
В качестве вариантов:
Способ 1: проверить индексацию по мелким разделам сайта, потом сложить данные.
Такую проверку в любом случае провести крайне полезно. Понимание картины с индексацией разных частей сайта помогает лучше оценить его состояние, проблемы и перспективы. См. мой недавний пост о новом инструменте, который позволяет делать это в автоматическом режиме.
Способ 2: добавить к оператору слово, встречающееся на всех страницах сайта.
Таким образом мы усложняем запрос и сужаем поиск. В некоторых случаях это дает хорошие результаты:
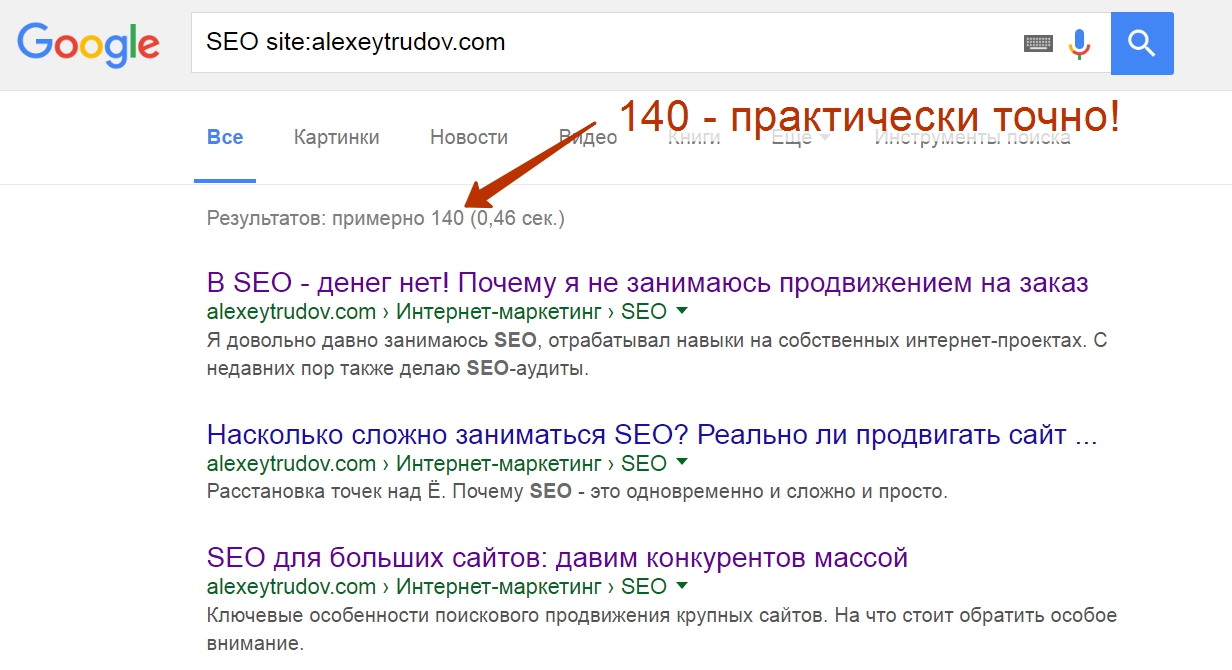 На 1 страницу меньше, чем при листании в конец выдачи. Вполне закономерно – на странице инструмента для принятия рациональных решений этого слова нет. Если попробовать запрос с исключением слова SEO (-SEO site:alexeytrudov.com), то как раз найдется эта страница в единственном экземпляре.
На 1 страницу меньше, чем при листании в конец выдачи. Вполне закономерно – на странице инструмента для принятия рациональных решений этого слова нет. Если попробовать запрос с исключением слова SEO (-SEO site:alexeytrudov.com), то как раз найдется эта страница в единственном экземпляре.
Увы, это работает не всегда. Слово “блог” тоже встречается на всех страницах. Но его добавление позволяет найти не все результаты:
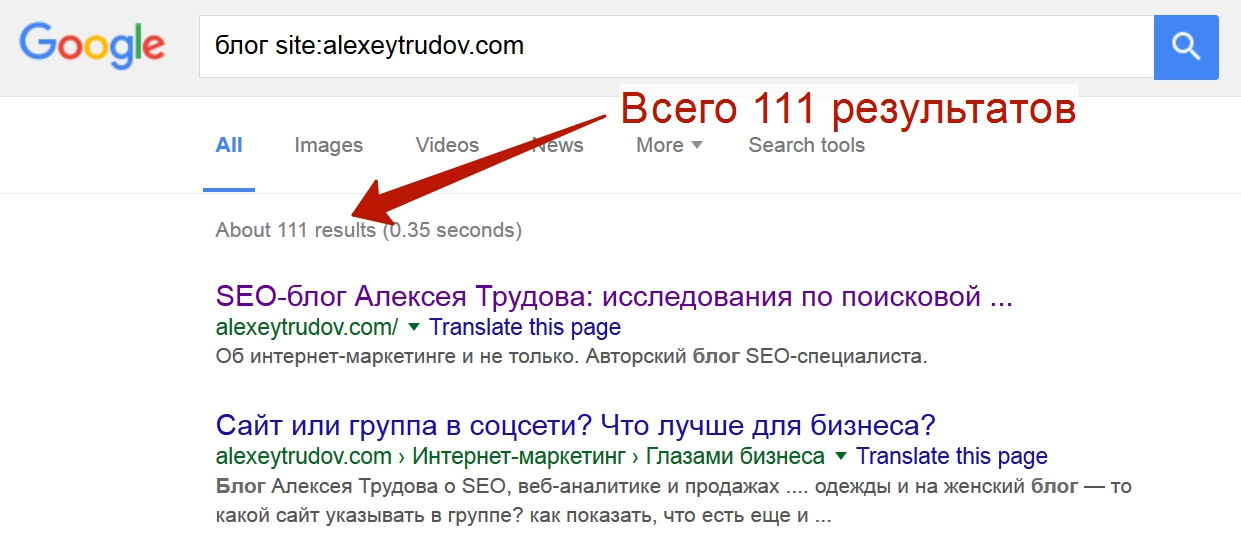
У меня есть несколько гипотез в отношении причин такого поведения поисковика, но они требуют дополнительной проверки. А пока, для практики, запомним, что метод добавки слова сильно ограничен. Лучше использовать его вместе с фильтрацией по разделам.
Замечу, что для больших (сотни тысяч страниц) проектов добиться адекватной оценки количества проиндексированных страниц еще сложнее. Это лишний аргумент за внедрение на таких сайтах систем внутренней SEO-аналитики (см. пост “Рулим оптимизацией с комфортом. Постраничная аналитика“) – они окупаются.
Конечно, все оговорки здесь не значат, что задача вообще не решается. Ее долго и муторно решать вручную, но если автоматизировать рутину, то вполне можно добиться высокой точности данных. Я придумал и протестировал пару относительно сложных алгоритмов, они показали хорошие результаты. Если финальные тесты будут удачными, то планирую использовать их в одной из новых версий сервиса SEO-прорыв. Пока там применяется не вся схема, точность выше, чем у обычного поиска через site:, но еще не идеальна, имейте это в виду.
Такие дела. Даже за банальнейшим вопросом поисковой оптимизации может скрываться бездна нюансов. Попробуйте впихнуть их все в чек-лист и не утонуть.



Это бомба! Как я раньше жил, не зная этой информации?!!! Автор пиши есчо!
спасибо вам Алексей-)
Для своего сайта “общее число страниц” надо смотреть через серч консоль. Оператор site:* для домена/разделов имеет смысл юзать только для проверки “а не сожрал ли гугл что-то лишнее”. Ну и понятное дело, все приоритетные страницы надо отслеживать по info:*, задолбит капча, но куда деваться.
Спасибо за дополнение!
Писали на серче про проверку индексации с помощью Python – https://www.searchengines.ru/urls-not-indexed-google.html Должен быть 1 пряморукий программист – и проблема решена. Наверное 🙂
Статью на серче можно заменить советом “возьмите программиста, который сможет спарсить выдачу Гугл по запросам типа info:ссылка в цикле”. 🙂 С этим все понятно, такой скрипт вам на веблансере набросают и установят за 30$.
Я же пишу немного о другой задаче – быстро, без больших ресурсов и войны с капчей Гугла проверить число страниц в индексе (причем их списка у нас тоже нет, т.к. проверяем чужой/новый для себя сайт).
Спасибо, метод “включения повторяющегося слова” дает более точную картину, проверил на одном из своих сайтов (~100тыс страниц). Все же это примерная оценка, но для “оценить сайт в выдаче навскидку” сойдет