
Cеошная общественность бурно обсуждает новый алгоритм Яндекса Баден-Баден. Не особо продуктивное занятие, на мой взгляд. Слишком мало времени прошло. Вряд ли у кого-то накопились достоверные наблюдения по хорошей выборке пострадавших сайтов. Тем более наивно ждать эффективную методику снятия. Да что там, пока даже неизвестно, включен ли алгоритм на полную мощность.
Ясно только одно: оптимизацию теперь нужно делать еще аккуратнее и тщательнее. Поэтому нелишне будет разобраться в достаточно редко упоминаемом факторе текстовой релевантности – YMW. Он основан на размере минимального куска текста, включающего максимальное количество встречающихся в документе слов запроса.
Статья Александра Сафронова “Тестирование простой ранжирующей формулы”
В публикации описана формула ранжирования, разработанная сотрудниками Яндекса для экспериментальной оценки отдельных факторов. Среди них – в первую очередь хорошо знакомые оптимизаторам вариации BM25 а также пара метрик, оценивающих близость слов запроса.
Вот описание одной из них – YMW:

Впали в уныние от нагромождения формул? Напрасно! Разобраться не так сложно. Внимательно читаем легенду:

Вторая же часть формулы представляет поправку на тот случай, если в тексте документа содержатся не все слова запроса. Она оперирует понятием “вес слова”. IDF (inverse document frequency) – оценка частоты встречаемости слова во всей базе документов в поисковой системе. Эта величина используется во многих других факторах текстовой релевантности.
Теперь опустим конкретные знаки действий и логарифмы, просто отметим, какие параметры увеличивают итоговую оценку, а какие уменьшают.
- Минимальный размер “окна” в котором встречаются все слова запроса – находится в знаменателе дроби. Чем он меньше, тем выше значение фактора.
- Количество слов запроса, встречающиеся в документе – вычитаются из знаменателя. Чем больше, тем выше значение фактора.
Видите? От всей сложной формулы остается всего два параметра, специфичных для рассматриваемого фактора. Чуть ниже будет еще более наглядное объяснение, а пока проясним важный вопрос:
Стоит ли вообще учитывать этот фактор?
Рассматриваемая статья достаточно старая, выпущена еще в 2010 году. Тем не менее, я считаю, что по крайней мере общие тенденции, выделенные выше, остаются актуальными. Вот несколько причин:
- Судя по свежему докладу об устройстве поиска Яндекса, статья описывает вполне актуальные подходы к тестированию новых факторов ранжирования (вторая часть публикации).
- Фактор упоминается в ТЗ на SEO-текст сравнительно редко. Поэтому поисковым системам не было нужды его отбрасывать под давлением оптимизаторов. Вообще он актуален для длинных запросов, под которые редко продвигают специально.
- Группировка слов запроса в пределах абзаца-двух характерна для качественного профессионального контента. Очевидно, что слова, связанные с конкретной темой будут сами по себе тянуться друг к другу: их связывает общая мысль.
- В той же статье указан фактор “кучности”. То есть близость слов – это реально важный фактор, поисковик пытается “зацепить” его разными способами.
Думаю, достаточно. Переходим к самому интересному – практике и выводам.
Как неосторожный оптимизатор может уменьшить релевантность текста
Если мы имеем дело со страницами, которые не претендуют на другие ключи, кроме вставленных в title, то фактор не будет особо значим. Ясно, что в этом случае мы получим очень маленькое “окно” – сам title. А вот если мы хотим сэкономить на создании страниц и одной статьей охватить десяток-другой среднечастотников и сотни их мелких НЧ-расширений – то учитывать YMW необходимо.
Сначала пример как делать НЕ надо (заодно буквально в картинках разберем суть фактора).
Допустим, у нас есть статья, в которой упомянут определенный ключевик:

Потом до нее дотянулись шаловливые ручки оптимизатора и он решил расширить семантику а также напичкать текст модными LSI-словами. Загнал запросы в сервис генерации ТЗ, вытащил уйму расширений и тематичных слов. Отдал копирайтеру. Копирайтер не заморачиваясь дописал лишний абзац, куда густо натыкал затребованные термины. На выходе получилось это:
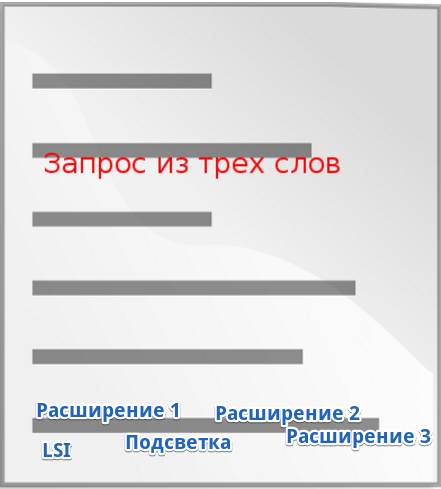
Все что надо – упомянуто. Ура?
Не совсем. Давайте прикинем YMW для “запрос из трех слов + расширение 1” до и после доработки. Смотрим сделанный выше вывод из формулы: чем меньше размер “окна” содержащего все слова запроса и чем больше слов из запроса встречается в документе – тем сильнее оценка фактора.
До:
- размер окна, включающего все слова: 3 (они просто идут вместе).
- число слов: 3 из 4
После:
Окно резко выросло!
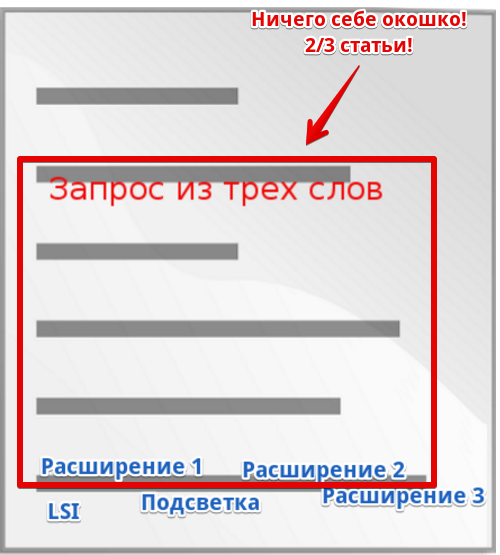
То есть мы что-то добавили к итоговой оценке YMW за счет вхождения всех слов запроса и одновременно убавили, сделав окно огромным. Итоговое значение при этом могло упасть. Оцените порядок цифр в знаменателе первой дроби: для первого случая это (3 – 3 + α) а во втором что-то вроде (500 – 4 + α).
Конечно, другие факторы при этом могут сыграть в плюс (вхождение всех слов запроса – сильный сигнал). Но полного эффекта, который могло бы дать расширение семантики мы не получим.
Заметьте кстати: негативное влияние бездумного добавления ключей прослеживается на примере даже простого фактора ранжирования, без привлечения факторов антиспама.
Выводы
- Фактор YMW имеет смысл учитывать в текстовой оптимизации. Особенно с учетом резко негативного отношения поисковых систем к традиционным методикам, опирающимся на число вхождений.
- При продвижении под кластер ключей необходимо следить за близостью ключевых слов и расширений запроса в пределах страницы. Принцип максимального сокращения межсловных расстояний нужно применять не только к основным ключевым словам. Требуется проектировать страницу так, чтобы ему соответствовал весь набор поисковых фраз, включая микро-НЧ, предусмотреть которые невозможно.
- Добавление на страницу связанной лексики без учета расположения основных ключей не даст полного эффекта.
- Для оптимизации под длинный хвост в отношении YMW лучше всего подходят тексты с четкой структурой, разбитые заголовками на небольшие блоки. При этом каждый блок должен быть посвящен раскрытию конкретной под-темы и содержать максимум лексики, которая с ней связана. Нежелательна ситуация, когда запрос используется в одном блоке, а важное расширение в другом.



Ужаснулся от вида формулы)))
Очень интересно применить это в написании статей. Спасибо огромное за статью!!!
Пожалуйста, удачи!
Тот случай, когда вроде разобрался в сути формулы, но не разобрался в сути текста. Такое ощущение, что текст и формула о разном. Формула о том, как оценивать релевантность текстов, в которых встречаются не все слова запроса (довольно редко сегодня событие: все более-менее нормальные, по крайней мере трехсловные запросы уже разобрали). То есть говоря проще – способ превратить пересечение множеств слов запроса и текста документа с одной стороны и “кучность”, то есть размер минимального окна со словами с другой стороны в численную величину для оценки релевантности.
А откуда именно это следует? Можно точную цитату?
Если встречаются не все слова запроса – это частный случай, вот и все. Авторы же не отрицают полезность изначальной формулы, которая не учитывала эту возможность.
А, да, я упустил. И из заголовка (“длинный хвост ключей”) и из текста (“расширить семантику”) упоминалась необходимость оперирования длинными запросами. В таком случае все для меня встает на свои места. Повторюсь для себя: что было – не полное вхождение слов длинного, расширенного запроса, но компактное “окно”, что стало – более полное вхождение, но размытость по тексту. Не факт, что стало лучше.
Далее, если автор одобрит комментарий )). Не понятен разобранный практический пример. Имеем запрос из трех слов, запрос встречается в тексте документа. Оптимизатор в новой версии текста не убрал запрос, но дополнил текст “модными LSI-словами”. Если с точки зрения поисковика наличие тематических терминов полезно для ранжирования запроса – это вовсе не плохо. Но это тема другой статьи. Если рассматриваем фактор YMW – то окно никак расшириться не может, так как запрос явно присутствует в тексте. Слова не разбросаны, они в наличии в полном объеме, не вижу причин “расширять окно”.
Обижаешь)
Я не одобряю только бессмысленные комментарии/спам. Критика приветствуется.
Именно. Я говорю только, что “полного эффекта, который могло бы дать расширение семантики мы не получим”. Не значит, что его нет вообще.
Может 🙂
Потому что мы рассматриваем более длинный запрос, состоящий из старого трехсловника и слова-расширения. Например, трехсловник: “продвинуть страницу сайта”, а запрос, который рассматриваем – “продвинуть страницу сайта быстро”.
Алексей, ты не написал, как расшифровывается название фактора YMW ?
Прямого упоминания расшифровки в статье нет, поэтому не стал писать от том, чего не знаю наверняка. Для себя я расшифровал как Yandex Minimal Window.
Хм, актуально и полезно. Спасибо. Попытаюсь внедрить в ТЗ..
Пожалуйста! Расскажи как-нибудь об опыте внедрения 🙂
Ты в статье упомянул сервис генерации тз, подскажи, какой-нибудь удобный сервис или каким ты пользуешься?
Они все примерно одинаковые. Везде нужно руками сильно допиливать. Напишу как-нибудь на эту тему подробно.
Алексей, хорошо бы дать также визуальный пример, когда такое расширение “даст полный эффект”.
Владимир, когда запрос и его расширение располагаются рядом. Думаю, несложно представить, а то корявых картинок и так в статье много 🙂
>>Заметьте, кстати: негативное влияние бездумного добавления ключей прослеживается на примере даже простого фактора ранжирования, без привлечения факторов антиспама.
Речь о том, что большое окно не даст достигнуть максимального эффекта? Или к чему тут антиспам упомянут?
>>…страницу так, чтобы ей соответствовал весь набор поисковых фраз,
включая микро-НЧ, предусмотреть которые невозможно.
Непонятный пассаж, поясните.
Антиспам упомянут, потому что с подобными текстами по идее как раз он должен бороться. То есть отдельные факторы, нацеленные на выявление неестественных текстов. Но как видим, даже обычный фактор, повышающий рейтинг страницы, может страдать от такой оптимизации.
Смотрите. Все эти микро-НЧ как раз берутся из текста. Если мы четко структурируем контент на странице и не используем “воду”, то расстояния между основным запросом (в подзаголовке h2) и его расширениями (в тексте под ним) будут небольшими, что и увеличить YMW. А если страницу вообще никак не проектировать и писать в стиле “что вижу то пою”, то даже если охватить множество разных слов, входящих в запросы, они будут рассеяны по тексту и размер окна для каждого будет большим.
Например, есть статья: как похудеть в домашних условиях?
H2 – как похудеть в домашних условиях
H3 – быстро
H3 – без диеты
H3 – с помощью упражнений
Правильно ли я понял, что раскрывая каждый пункт плана статьи, нужно подбирать нужные слова в тексте?
Например, разберем h3 – с помощью упражнений
Внутри пункта я расскажу о нужных упражнениях и все? Или сюда еще нужны lsi – фраза и синонимы?
И если, сделаю все, как нужно, могу рассчитывать на 30 и более посетителей с одной статьи в сутки?
Уже месяц пытаюсь докопаться до истины. Подскажите, куда копать…
Да, желательно относящиеся к упражнениям “LSI” вставить именно сюда. Хотя если вы пишете адекватный текст, то они будут в нужном месте естественным образом. Важно удалять “воду”.
А вот это зависит и от множества других факторов. Конкуренция, хостовые характеристики, ссылки…
Спасибо, начинаю понимать.
Но как мне узнать нужные lsi – фразы к каждому конкретному пункту в статье.
Или просто смотрим lsi конкурентов, и видим, что пара фраз подойдет в один абзац нашего текста и соответствует тематически запросу в h2, а другая пара-тройка в другой абзац и соответствует основному запросу в h3.
Нужен глубокий анализ.
Что если, взять статью, на которой есть трафик, 10 человек в сутки и добавить туда важные lsi в нужные места.
Через сколько примерно времени можно будет увидеть последствия такого эксперимента?
Скорее тщательно собираем семантику и изучаем запросы. Где брать LSI – буквально сейчас над этим работаю, возможно скоро удастся выпустить инструмент для автоматизации.
Достаточно быстро. В течение нескольких недель можно заметить эффект – но скорее по трафику, чем по позициям.
Возможно будет интересно: http://alexeytrudov.com/web-marketing/seo/keys-ozhivlenie-starogo-sayta.html