
Едва опубликовал исследование алгоритма Баден-Баден, как меня буквально завалили вопросами про конкретные цифры для выявленных показателей. На что ориентироваться? Какой уровень водности или там индекса биграммы/униграммы считать хорошим, а какой – плохим? К чему стремиться при доработке текстов? Где буйки, за которые нельзя заплывать?..
Вопросы совершенно закономерные. Безусловно, понимать точные критерии попадания страницы под фильтр было бы просто здорово.
Однако эта задача очень сложна. Поймать различия на нескольких десятках сайтов по отдельности и усреднить их для всей выборки сравнительно просто. Еще более важно, что в этом случае мы можем сравнительно уверенно интерпретировать данные. Хостовые факторы картину не искажают, абсолютные различия переведены в проценты, благодаря чему их можно сравнивать. Просто копаем в сторону самых сильных отклонений и все.
Благодать, основные тенденции выявлены. На практике можно проделать аналогичное исследование для любого сайта и найти самые критичные проблемы конкретных текстов.
Если же просто найти среднее значение текстовых метрик у страниц, попавших под Баден-Баден, то эти данные сами по себе мало что будут значить. Мы не можем быть уверены, отловленные цифры будут актуальны для другого сайта в другой тематике.
В целом, мое мнение по этому вопросу совпадает с тем, что писал Станислав Ставский:
Если попытаться определить пороги срабатывания алгоритма, то это практически нереальная на мой взгляд задача.
В выборках всегда будут примеры, которые должны упасть, но не падают. И, возможно, наоборот.
900 факторов против одного-двух факторов текстового антиспама – всегда будут ситуации, когда документы будут вытягиваться наверх другими сигналами.
Тем не менее, даже сомнительные ориентиры могут пригодиться (главное не забывать, откуда они взялись и не считать их высеченными в камне). Попробуем их выделить, чтобы иметь отправную точку для анализа, задать систему координат.
Хотя, зачем я вру. Главная задача – иметь ссылку, которую можно отправить в ответ на вопрос “много или мало, когда в анализе текстов в bez-bubna.com получаются такие цифры”:
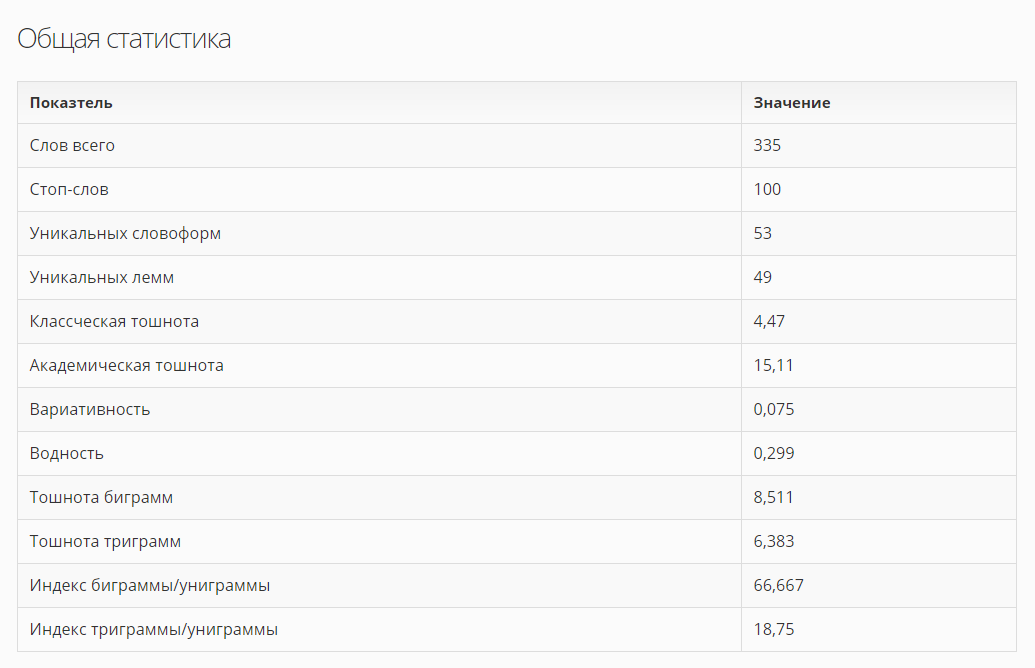
Методика: что и как считаем
Выборка – та же, что и в прошлом исследовании (благо, для этих страниц уже посчитаны все значимые текстовые метрики, определено, попал ли url под санкции, отброшен откровенный спам). Всего 4297, из них под Баден-Баденом 2772.
Однако теперь мы не разбиваем выборку по сайтам (нас интересуют универсальные цифры!), а смотрим средние значения показателей по всем url сразу, сравнивая “хорошие” и “плохие”.
Разумеется, любая разница между средними величинами могут оказаться случайной. Крайне важно отличать истинные различия от случайных. К счастью, тут не нужно изобретать велосипед – метод для проверки статистической значимости найденных различий появился более века назад. Это t-критерий Стьюдента. Интересующиеся могут загуглить или почитать самое простое объяснение, какое я только встречал на сайте “Статистика и котики”.
Для понимания этой статьи достаточно помнить, что с помощью t-критерия вычисляется вероятность отсутствия различий между средними из двух выборок. Грубо говоря, если для той или иной метрики (например, тошноты) такой шанс больше 1%, то считаем разницу по параметру не доказанной. Если меньше – то берем на вооружение и рассматриваем среднее значение для “плохих” страниц как опасный порог (возможны и другие интерпретации, важнее всего наличие/отсутствие различий как таковое).
Результаты по средним значениям и t-критерию
Вот моя рабочая табличка:
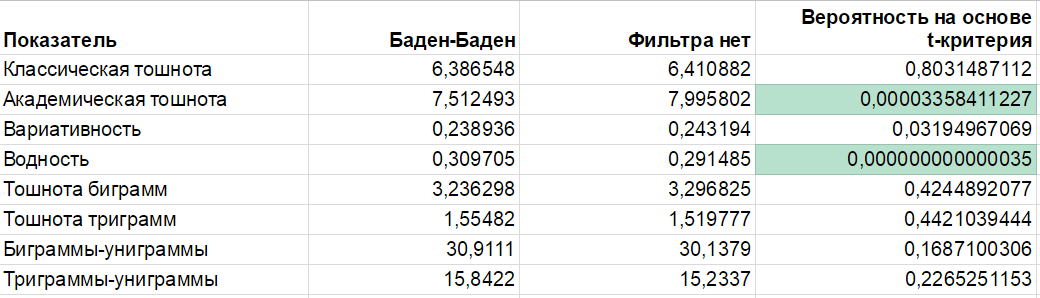
Долго вглядываться в нее не надо, главный вывод – статистически достоверные различия демонстрируют только средние значения по академической тошноте и по водности (вероятность значительно меньше 1%, выделено зеленым). Все остальное принимать во внимание нельзя.
Полезным ориентиром можно считать только порог по водности. Видим, что среднее для плохих страниц почти 0,31, а для хороших – 0,29. В общем-то, результат ожидаем. “Вода” – естественная часть любых статей, но даже небольшое перенасыщение стоп-словами ухудшает качество текста. Это как машинное масло: без него никуда, но если перелить – мотор не обрадуется.
Конечно, “нормальная” водность может сильно меняться в зависимости от тематики (например, в юридических текстах много перечислений и мало вводных оборотов, а в статьях о литературе скорее наоборот).
Второй параметр, для которого различия достоверны – академическая тошнота. Вряд ли он особо нам поможет. Тем более что из таблицы можно сделать вывод – “пихай побольше ключей и будет хорошо”. Ведь на страницах под фильтром тошнота ниже. Этот парадокс я подробно разобрал в предыдущей статье.
Можно ли найти дополнительные пороги? Можно!
Введем поправку на водность
Итак, мы получили еще одно свидетельство в пользу того, что тексты с высокой водностью Яндекс не любит. Естественно, мы хотим знать больше. Что еще ему может не нравиться, когда с водностью все в порядке? Сформируем новую выборку проблемных страниц. Возьмем для анализа только те, где водность не превышает 0,3:
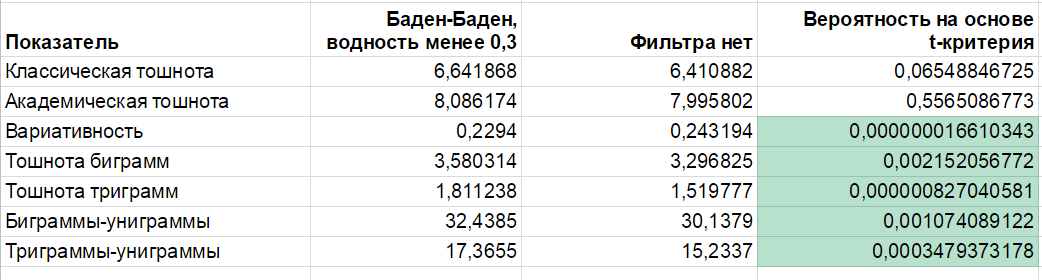
Ого, так куда интереснее!
- Исчезла какая-либо статистическая значимость в отношении тошноты. По всей видимости, она и правда никак не влияет на наложение фильтра (напоминаю, что я работал с выборкой достаточно качественных сайтов, где этот показатель не зашкаливал).
- Появились значимые различия для показателя вариативности. Впрочем, в абсолютном выражении разница невелика: 0,23 против 0,24. Как и водность, это весьма устойчивый показатель, с небольшой изменчивостью.
- Наконец, есть достоверная разница (обратите внимание на количество нулей в четвертом столбце!) по тошноте биграмм и триграмм, индексам биграммы-униграмы и триграммы-униграммы.
Выводы
Пропущу миллион оговорок и напоминаний о том, что реальная картина сложнее, чем ограниченная выборка, что различие по параметру еще не говорит о причинно-следственной связи и т.д. и т.п. Надеюсь, это и так понятно. По уму, конечно, нужно строить модель с использованием логистической регрессии. Проще говоря – подбирать формулу, которая бы определяла вероятность попадания страницы под фильтр на основе сразу всех значимых факторов. Я двигаюсь в этом направлении, но прогнозировать что-то сложно, поэтому пока работаем с тем, что есть.
Итак, отправными точками для анализа страниц-кандидатов на попадание под Баден-Баден можно считать:
- Водность 0,31 и более.
- Вариативность 0,23 и менее.
- Тошноту биграмм 3,6 и более
- Тошноту триграмм 1,8 и более.
- Индекс биграммы/униграммы 32 и более.
- Индекс триграммы/униграммы 17 и более.
Важное замечание: сам по себе индекс биграммы/униграммы и триграммы/униграммы никак не может говорить о том, что, что страница “плохая”. Он может быть высоким в случае, если в тексте мало и n-грамм и слов из их состава, которые встречаются отдельно. Это нормальная ситуация. Поэтому обращайте внимание на индексы только если тошнота n-грамм тоже высока.
p.s. Обещанный материал с практическими рекомендациями по борьбе с Баден-Баденом тоже будет. Собственно, это должно было быть его вступление. Однако написав огромное руководство по SEO-аудиту, я понял, что мне (и вам) нужно отдохнуть от постов, которые и проскроллить-то нелегко.
p.p.s. Вместо материала провел вебинар. Ознакомьтесь обязательно, чтобы убедиться, что верно понимаете смысл всех порогов. Несмотря на все мои предостережения в этой статье их часто воспринимают как жесткое правило – абсолютно неправильный подход!



Прочитав этот текст, я понял всю ситуацию по Баден-Бадену. Но что значит слово “удачи” в конце статьи?
Просто пожелание удачи в завершение статьи. Безотносительно к теме. Убрал, чтобы не путало 🙂
А какой объем выборки ? И сколько страниц под Баденом и без него ?
Добавил данные в статью.
А процесс формирования выборки описывал в прошлом посте.
Спасибо.
1. Предложение
В “Анализе текста” таблицу “Общая статистика” сделать более информативной. Подсвечивать “плохие” показатели и выводить рекомендованные.
2. в Базе знаний можете привести примеры как повлиять на такие показатели как “вариативность”, “индекс биграммы/униграммы”, “индекс триграммы/униграммы” ?
Спасибо за идеи, подумаю над этим.
Присоединяюсь к предложению 1.
Присоединяюсь. Особенно ко второму пункту. Сервис показал данные, есть усредненные показатели риска, за что огромное спасибо Алексею за проделанную огромную работу. Но как все исправить? В частности никак не вникну, что переделать, чтобы индексы понизить?
Дина, эти индексы показывают, насколько часто вы используете определенные устойчивые сочетания (чаще всего это ключевые слова). Одна из типичных проблем “плохих” статей – перенасыщение ключевыми словами. При этом общее число вхождений может быть не очень большим, но ключевики расположены в тексте неестественно (постоянно сбиваются в биграммы и триграммы).
Чтобы снизить – удаляем/разбиваем/заменяем синонимами самые частые биграммы. Особенно если это можно сделать без потери смысла (а часто так и бывает).
Посмотрите недавний вебинар, должно стать понятнее: http://alexeytrudov.com/web-marketing/seo/webinar-baden-baden.html
Ну и в любом случае эти показатели – только ориентиры, в каком направлении двигаться. Не стоит слишком сильно на них зацикливаться. В приоритете – качество текста в “человеческом” понимании.
За цИфри спасибо-)
Иногда достаточно наличие пары тройки неестественных речевых оборотов в тексте, чтобы попасть под Баден-Баден.
Да, тоже встречал такое. Правда обычно в сочетании с обильной водичкой.
Алексей, а какой словарь водных слов использован?
Где бы себе словарь такой найти в качестве старта для разработки своего?
Вводные слова – смиксовал традиционный короткий список (“который”, “какой”, “такой”…) который где-то загуглил, стоп-слова от Контентмонстра частично + добавил кое-что в ходе тестирования bez-bubna (инструмента по дооптимизации).
Делиться конкретным списком не готов, так как он связан с УТП сервиса – выявленные пороги напрямую зависят от того, что считается водой.
Спасибо большое за материал! Планируется ли API у сервиса проверки текстов?
Буквально вчера задумался над API. Начали поступать похожие вопросы. Видимо, придется сделать 🙂
Ждём продолжения.
Ктото может пояснить что такое “вариативность” и как она считается?
Справка по сервису, например 🙂
Неделю назад получил фатальное предупреждение в вебмастере по сайту http://modamio.ru . Баден-Баден.
Постучал в ТП Яндекса с просьбой разъяснить – “за что” и попросил привести примеры.
Четко указали на эту страницу:
http://modamio.ru/rabota-v-modamio
Но суть в том, что трафик у сайта с Яндекса провалился в нуль.
Т.е. санкции наложены на весь сайт.
Может вам еще один крупный донор будет полезен в анализе.
Как вы считаете, стоит ли закрыть описание на страницах товара в noindex ?
Спасибо.
От хостового скорее всего noindex не спасет. Правьте тексты.
Связывался с Платоном.
Он четко дал понять, что обрамление текста в тег – не поможет для снятия санкций.
Цитирую:
“Нет, оборачивание контента в тег noindex исключает его только из процесса формирования поискового индекса, но он может использоваться другими способами, например, для обнаружения нарушений на сайте.”
Спасибо за интересную цитату!
А безбубна умеет искать страницы, которые давали трафик с гугла, а потом стали меньше давать? А запросы в гугле, по которым снизился траф?
Михаил, страницы где меньше пока нет (но будет, эта опция в разработке), только те, где полностью исчез.
Запросы – да, если подключен Search Console. См. в демо https://bez-bubna.com/demo/index.php?section=lost-traffic – последний раздел.
В search console есть данные по 22.06 включительно, а данный анализ учел данные по 18.06. Изменения на сайте были 19.06 🙂
Там считаются полные календарные недели. Чтобы адекватно сравнить количество показов/кликов и для простоты восприятия.
Все достаточно запутано и неоднозначно. Вы, Алексей, сами это подтверждаете (есть куча других факторов, кроме текстовых).
Здается мне в таком случае для статейников лучше всего нанимать проф. филолога, чтобы вычитывал и правил. И тогда думаю никакой Баден не будет страшен.
Что думаете по этому поводу, Алексей?
Вполне вариант.
Только надо понимать, что поисковики пытаются оценивать содержательность контента. Филолог, который в теме не разбирается, вряд ли сможет исправить “воду”, даже если и причешет с точки зрения языка.
Приветствую, по моему сайту (анализ 400 страниц под Баденом и 300 не под Баденом) вышло, что индексы биграмм/уни и триграмм/уни на Баден-страницах ниже индексов на незафильтрованных.
Есть разница логичная лишь у тошноты биграмм и триграмм, на Баден-страницах она чуть-чуть выше (но при этом, ниже твоих значений в статье, что говорит о том, что фильтр может быть и от 1.1 тошноты триграммы, например).
Вполне возможная ситуация.
Это тоже возможно, но я бы скорее стал копать в сторону других факторов – водности, общей уместности контента на странице и т.д. Водность возможна не в техническом смысле (много стоп-слов), а просто как факт отсутствия полезной информации.
Алексей, скажите пожалуйста, при расширенной проверке только текст проверять или стоит всю страницу загружать, с заголовком и всем остальным, то есть, как её анализируют ПСы?
Заголовок я думаю в любом случае надо включать. Все остальное – зависит от сайта. Если там больше особо контента нет кроме статьи, какие-то “технические” виджеты только – то не стоит их анализировать, лишний шум. Ну а если к статье много комментариев, например – то их тоже стоит включить.
Ещё, забыла. Содержание в статье сильно повышает индекс биграмм, его следует тоже учитывать, значит оно даёт переспам?
Не было отдельных исследований, думаю, стоит все-таки включать в анализ. Ведь оно даст значимое превышение только если n-грамма встречается сразу в нескольких заголовках, а не одном.
Решил таки попробовать ваш сервис. Всё время думал что у меня проблема именно с биграммами/триграммами, проверил 2 статьи (справедливости ради, я их ранее уже чуть чистил от них ) и по этим двум показателям у меня всё нормально, как и по другим, но вот вот с водностью есть небольшая проблема. По первой по всему документу имею водность 0.348, что я так понимаю прилично за допустимую линию. По второй, по статье водность 0.344, а по всему документу 0.316, что буквально вот вот чуточку превысило предел. И вроде хочу поверить что проблема в воде, но есть наблюдение, если я в триграмме разрываю первые 2 слова (биграмму), то позиция улучшается на 20-30 пунктов. То есть, мы имеем гороховый суп с курицей на 49 месте, если я пишу гороховый с курицей суп или суп с курицей гороховый, то мы поднимаемся на 15 и 20 место, притом что по странице тошнота биграмм и триграмм 2.466 и 1.37, индекс 25,352 и 14.085, а по статье тошнота 2.454 и 1.431 и индекс 24.49 и 14.583, далеко тут до нарушения. Разрывание суп с курицей не помогает, так и остаёмся на 49 месте. По идее, если ПС могут отделить всё лишнее от самой статьи, то есть комменты, метатеги, меню и прочее, то они могут увидеть саму статью с водой 0.344? Если да, то нельзя надеется что комменты, метатеги и прочее могут вытянуть страницу? А утопить они могут страницу, если в статье всё идеально, а в комментах вода и переспам?
Теперь думаю что с этим делать? Пробовать всё же избавляться от воды? Не подскажете, на какой сервис бесплатный ориентироваться для контроля по воде, адвего что должен показывать? Просто накладно каждую правку проверять у вас, готовый финиш уже ладно, повторно можно, а промежуток? Заранее спасибо, если ответите на мои вопросы.
Денис, я бы так сильно не зарывался в мои параметры :). Не стоит под них подстраиваться. Как ни банально, но нужно улучшать сам текст.
Прочитайте, если еще не видели: http://alexeytrudov.com/web-marketing/seo/eshhe-raz-o-baden-badene.html
Показатели в анализе – это только сигналы, где может быть проблема. Раз показывает высокую водность – попробуйте добавить “сухого” контента, например, маркированный список с перечислением важных фактов. Он в любом случае сделает статью полезнее.
С адвего мало работал в последнее время, не могу ничего подсказать.
Учитывается весь контент, но по-разному. Для информационных запросов важен основной текст.
Легко. Я даже ставил эксперимент: http://alexeytrudov.com/web-marketing/seo/avtomaticheskaya-vstavka-klyuchevikov.html
Спасибо за ответ. К сожалению я уже замучался искать проблему. Сейчас вот руками перепроверяю каждую статью, есть где конкретно ужас, есть где не очень, но кулинарный сайт с посещаемостью 3-5 тысяч скатился до 500… Но уже вижу одно, академ тошнота точно не важна, что вы уже не раз упоминали. Есть страницы где различные сервисы типа Кулаков и Арсенкин (не посчитайте за рекламуу) видят фильтр и страницы, которые были в топ-20, сейчас на 48-49-х местах, ожидаемо должны быть в том же топе, но убирание точных вхождений (Н-грамм) пока почти нигде ни к чему не привело, хотя их правил уже раз по 5 некоторые… Местами вижу что мало слов из этих Н-грамм, местами я их сам убрал и академ тошнота стала 7.1% например, что ни есть нормально, у конкурентов 8-10. Ваш сервис удобен тем, что он показывает порог. Я сам где-то вижу что есть перебор, убираю, но точно не понимаю сколько надо убрать. А если это 2 параметра, то я их точно на глаз не определю, так что надеюсь эффект будет. Одну статью, по которой шло до 1000 посетителей в месяц (а сейчас 10), уже подчистил по вашим параметрам, пошёл делать дальше. О результатах отпишусь, надеюсь хороших)))
Пожалуйста.
Я бы посоветовал не упираться только в текстовые факторы. Причина падения может быть и не только в них.
Да, будет интересно.
Добрый день! Подскажите пожалуйста, при пакетном анализе текстов, при проверке статьи (только plain-текст), в него входит Тайтл или какой-то другой мета-тег? Просто почему-то показывается всегда на 1 больше биграмм, чем если проверить реально саму статью, непонятно как это учитывать и сколько реально лишнего именно в статье, так как часто по странице может быть в районе порога, а по статье 4.8 при пороге 3.6. Спасибо.
Денис, добрый день! Да, title учитывается (его нельзя не учитывать)
Проверил весь документ. Вроде с Тайтлом получается, А дескрипшн не учитывает, как и альт картинок? Просто пользуюсь ещё одним сервисом, он альт картинок, дескрипшн и кейвордс учитывает при анализе документа. А у вас они не учитываются ни при проверке статьи, ни при проверке страницы?
Все правильно. Сервис в первую очередь под Яндекс, поэтому alt не учитывается (легко проверить, что страницы не ищутся по уникальному alt в обычном поиске). Description также не участвует напрямую в ранжировании.
Снова здравствуйте. На какое-то время отлучался, сейчас вот решил проверить написанную статью и получил результат в виде тошнота биграммы 4.605, а 3граммы 3.29, но по факту имею всего – окорочка духовка – 3, майонез чеснок – 2, духовка майонез – 2 и окорочка духовка майонез – 2, духовка майонез чеснок – 2, автор имя приветствовать – 1
В Н1 – окорочка в духовке с майонезом и чесноком, в статье 1 раз – окорочка в духовке с майонезом и чесноком и в конце статьи – в окорочка в духовке, готовы.
Страница после добавления 2 апа была на 10 и 14 местах и вчера улетела на 40-е место, арсенкин и кулаков видят фильтр.
Но остаётся вопрос, а как выходить из этой ситуации? Ну ладно, в коце статьи уберу фразу – окорочка в духовке или оставлю только окорочка или разбавлю её. Но этого же будет не достаточно. Убрать вхождение из статьи или Н1 будет не правильно. Можно попробовать в Н1 или в статье, вместо – окорочка в духовке с майонезом и чесноком, написать – окорочка с майонезом и чесноком в духовке. Этого может быть достаточно? Если да, то где лучше трогать? Просто странно что такая реакция, казалось бы 1 полное и ещё 1 частичное вхожд в статье и такой результат… Заранее спасибо.
Денис, скорее всего дело не во вхождениях (по крайней мере во вхождениях главного ключа). Вы правильно пишете что особо убирать тут нечего. Причин, по которым обвалились позиции может быть много (например, накопились негативные ПФ). Я бы для начала посмотрел, нельзя ли улучшить текст в целом, сравнил бы с конкурентами по содержательности.
Результаты надо использовать осторожно. См. исследование метода, который лежит в основе этих сервисов.
Доброго времени суток. В приципе описанный подход интересный, но…
“Для понимания этой статьи достаточно помнить, что с помощью t-критерия вычисляется вероятность отсутствия различий между средними из двух выборок”.
Наверно не совсем так. T-коэффициент служит ориентиром для понимания того, насколько разница в значениях выборки статистически значима. Это означает немного другое – случайна эта разница или закономерна.
Было бы понятней читатаелю если бы вы описали как рассчитывали число степеней свободы и какой показатель вероятности (уровень значимости) использовали.
В таком варианте изложения пользователь должен принять ваши данные на веру и при попытки точного копирования этого подхода результаты могут не совпасть.
А вы вспомните, что такое статистическая значимость – тогда противоречия между определениями не будет.
Обратите внимание на количество нулей в выделенных зеленым фрагментах таблицы. Чтобы повлиять на выводы, результаты должны не просто “не совпасть”. Они должны отличаться на пару порядков.
У вас написано – “вероятность отсутствия различий”.
Различия в выборках и их средних значениях изначально есть. Строго формально, вы пишете – “он показывает, отличаются средние или нет”. Ну так и без коэффициента видно, что отличаются.
По этому, я бы вам рекомендовал перефразировать ваш вывод, чтобы не было недопонимания.
Ну, это мое мнение конечно. Хотя большинство конечно поверит на слово 🙂
Я же привык сомневаться во всем. Профессия такая.
Вы точно изучали статистику? Возможно, какую-то иную, чем я.
Да, изучал. Не нужно придираться к словам. Я смотрю на показатели вашей таблицы. Значения в выборках отличаются или нет? Если не отличаются, смысл еще что-то рассчитывать?
Не понял к чему это. Видно же что они отличаются. Но непонятно насколько значимы различия.
” Но непонятно насколько значимы различия.” – это и коню (мне) понятно. Думаю вы тоже поняли мою мысль. Но почему то сказали, что я человек не вчоный (не знающий, что такое статистика). 🙂
Есть такое понятие – двусмысленность. Так вот, тот кусок текста приводит к разночтениям в его толковании. По этому я вам и предложил изложить его более академически. Но я не вправе настаивать, как хотите, так и пишите – этоже ваш блог.
Не обижайтесь, пожалуйста.
Я много времени потратил, чтобы добиться баланса академичности и понятности. И не думаю, что стоит его нарушать. Даже для большей точности.
Не могу ответить на Ваше последнее сообщение.
Если Вы говорите, что убирать нечего, то каким образом тошнота биграммы 4.6, при пороге 3.6? Я же для того и проверяю, чтобы увидеть, есть перебор или нет. По поводу улучшить, то это новая статья, она ещё не успела дать ПФ чтоб её выкинуть из-за этого. Старые статьи которые 1-2 года давали 1000-10000 трафика в месяц и имели отказы в 10%, точно говорят что страницы были нормальные в плане информации, но что-то стало не так технически.
Да, но Сёрче один человек написал по поводу нграмм, типа делим нграмму на количество слов из неё и должно быть не более 0.1. То есть, если мы в статье написали 3 раза гороховый суп с курицей, то слов гороховый, суп, курицей в сумме должно быть получается около 30. Что вы скажете по этому поводу? Если это так, то учитываем только полную фразу или и части, гороховый суп и суп с курицей? Спасибо.
Этот порог – очень-очень условная штука. Для небольших текстов она легко может зашкаливать при низком уровне вхождений. Обязательно прочитайте памятку.
Я не доверяю любым жестко зафиксированным показателям. Для разных тематик и запросов адекватны разные характеристики, это очевидно. Тем более что пороги постоянно меняются.
Если бы все было так просто – я давно бы сделал сервис, который показывает, что именно нужно поменять, чтобы стало хорошо 🙂 Но текстовая оптимизация – действительно сложная штука, поэтому работаем с тем, что есть.
Алексей, добрый день! Можно вопрос не по теме статьи? В последние дни вновь что-то происходит с выдачей. Многие сайты потеряли в позициях очень много, и посещаемость заметно просела. ТОП опять колбасит, как после появления Бадена, и никто не может понять, что происходит. Вылетели статьи не только у меня, зацепило сайты всех моих знакомых веб-мастеров, и очень сильно.
На форумах предположения самые разные, но толком никто ничего не знает, а Яндекс как всегда отмалчивается.
Что вы думаете по данному поводу? Пожалуйста, хотя бы пару слов, в каком направлении думать.
Блин, уже не знаешь, что Яша еще придумает, и как подстраиваться. Хоть бы объясняли, чего хотят, мы же не гордые, мы все сделаем.
Галина, добрый день!
В последнее время не наблюдал падений, у которых были бы четкие общие признаки. Но, конечно, могли выкатить на отдельные тематики или типы сайтов. Напишите на почту примеры и дайте доступ к Метрике с Вебмастером (на alexeytrudov) для проблемных сайтов, возможно что-то и прояснится.
Да, Алексей, мой сайт тоже под раздачу попал. Мы искали хотя бы приблизительные признаки падения, но, увы. А Платоны как всегда отписались, мол с сайтом всё в порядке, никаких санкций нет, развивайтесь дальше. Но в какую сторону, если вот так всё на корню отрубили.
Ольга, можете прислать сайт на alexeytrudov@gmail.com; не факт что смогу разобраться, но если будут идеи – дам знать.
Спасибо большое, написала вам, очень надеюсь, что разберетесь, вы умный, тем более что под “раздачу” попало множество сайтов..
Пока не за что)
Посмотрим, что выйдет.
отправила